DeepSeek + Dify = ? 本地知识库!
前言
近年来,大语言模型(LLM)在社会各界都很有热度,各路 AI 层出不穷,比如 OpenAI 的 ChatGPT、Google 的 Gemini、X 的 Grok 和 我们中国国产的 DeepSeek 等等。 其中,DeepSeek 作为开源的 LLM,在本地推理方面表现出色,而 Dify 作为一款低代码 AI 应用平台,为 LLM 的使用和管理提供了便捷的解决方案。 各界人士都希望将 DeepSeek 和 Dify 结合,为他们提供本地知识库的智能问答。本文将介绍如何将 DeepSeek 以及其他一些 LLM 都接入到 Dify,为各位搭建一个半离线甚至于可以说完全理想的本地知识库。
系统要求
在开始部署前,请确保设备满足以下条件:
- 操作系统:Windows 10/11(64位)或 macOS Monterey(12.0)或 Ubuntu 22.04 及以上
- 内存:最低 16GB(推荐 32GB 以上以提升响应速度)
- 显存:最低 8GB(推荐 16GB 以上以提升响应速度)
- 存储空间:至少 20GB 可用空间(模型文件通常占用 10-15GB)
- 网络:稳定互联网连接(下载模型需 5-30 分钟,具体取决于带宽)
部署流程
一、基础环境配置
1. 安装 DeepSeek 模型
Windows/MacOS 用户在本地运行 DeepSeek 可以参考这篇文章: 本地部署 DeepSeek 模型完全指南。
Linux 用户可以按照以下方法快速安装:
-
安装 Ollama
1curl -fsSL https://ollama.com/install.sh | sh -
下载 DeepSeek 模型
1ollama pull deepseek-r1:8b -
启动 Ollama 服务
1ollama serve & -
测试是否成功运行
1curl http://localhost:11434/api/tags如果返回类似于
1{"models":[{"name":"deepseek-r1:8b"...说明模型加载成功。
2. 下载其他所需模型
-
下载
bge-m3:latest模型1ollama pull bge-m3:latest
如果你想完全离线化的话,可以在 Hugging Face 上下载以下模型
- Rerank 模型: BAAI/bge-reranker-v2-m3
- 语音转文本模型: FunAudioLLM/SenseVoiceSmall
- 文本转语音模型 fishaudio/fish-speech-1.5
然后找到 gguf 格式的模型,下载之后使用 ollama create 命令导入
例如:
|
|
-
如果没有的话,就需要下载
safetensors文件然后再进行转换 可以使用下面的一个范例脚本进行转换1 2 3 4 5from transformers import AutoModel import torch model = AutoModel.from_pretrained("fishaudio/fish-speech-1.5") model.save_pretrained("fish-speech-1.5-gguf", safe_serialization=True)然后使用
llama.cpp将其转换1python convert.py --input fish-speech-1.5-gguf --output fish-speech-1.5.gguf
3. 安装 Docker
1. Linux
Linux 用户可以根据这篇文章安装 Docker: Docker 的安装与使用,并根据自身网络环境选择是否配置镜像加速器。
然后安装 Docker Compose
|
|
2. Windows/MacOS
Windows/MacOS 用户需要到 Docker官网 安装 Docker Desktop 选择符合自己芯片的版本
-
Windows 用户直接根据指示安装即可,等待安装完成,然后点击 Close and restart 以重启计算机;
-
MacOS 用户:
-
打开下载的
Docker.dmg,拖动 Docker 图标到/Applications文件夹。 -
打开 Docker Desktop,根据向导完成初始配置
-
允许 Docker 访问 macOS 文件系统(如有提示)
-
如果你使用 zsh 或者 bash,可以添加环境变量来使 Docker 命令自动补全
1 2echo 'export PATH="/usr/local/bin:$PATH"' >> ~/.zshrc source ~/.zshrc
-
Windows 用户可以按 Win+R 键,输入 cmd 回车,打开命令控制行;MacOS 用户可以打开终端
输入以下命令验证是否安装成功
|
|
返回的信息类似这样
|
|
2.1 配置 Docker 加速器
在 Docker Desktop 上点击 “设置” → “Docker Engine” → 替换成下面的内容 → “Apple & restart”
|
|
4. 安装 Git
1. Linux/MacOS
Linux 或 MacOS 用户可以使用以下命令来安装 Git
|
|
2. Windows
进入 git Download 页面 然后点击页面上的 Download for Windows 进行下载,根据提示进行安装后,设置环境变量:右键“此电脑” → 属性 → 高级系统设置 → 环境变量 → Path → 编辑 → <你安装git的位置\bin>
安装好了之后,打开命令控制行/终端,输入 git --version 检测是否安装成功或者环境变量是否配置成功
大致输出:
|
|
5. 克隆 Dify 仓库代码并配置 Dify
1. 克隆 Dify 仓库代码
|
|
2. 修改 Dify 的配置文件
2.1 修改环境变量
修改 ./dify/docker/.env 文件
Linux 用 vim 打开,Windows/MacOS 直接使用对应的文本编辑器即可
添加/修改以下内容
|
|
2.2 修改 nginx 配置文件
修改 ./dify/docker/nginx/nginx.conf.template 模板配置文件
Linux 用 vim 打开,Windows/MacOS 直接使用对应的文本编辑器即可
修改以下内容
|
|
配置好了之后就可以使用下面的命令启动 Dify 了
|
|
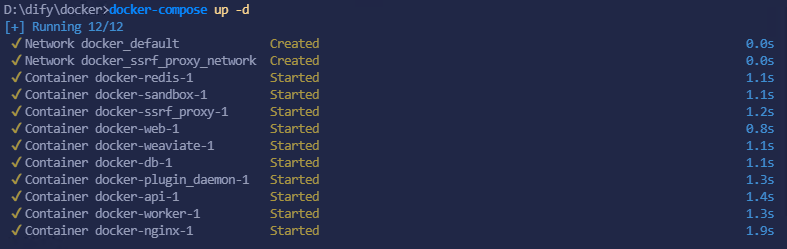
然后就可以输入 http://localhost/ 或者是 http://<你当前的IP地址>/ 来进入 Dify 中,随后初始化 Dify
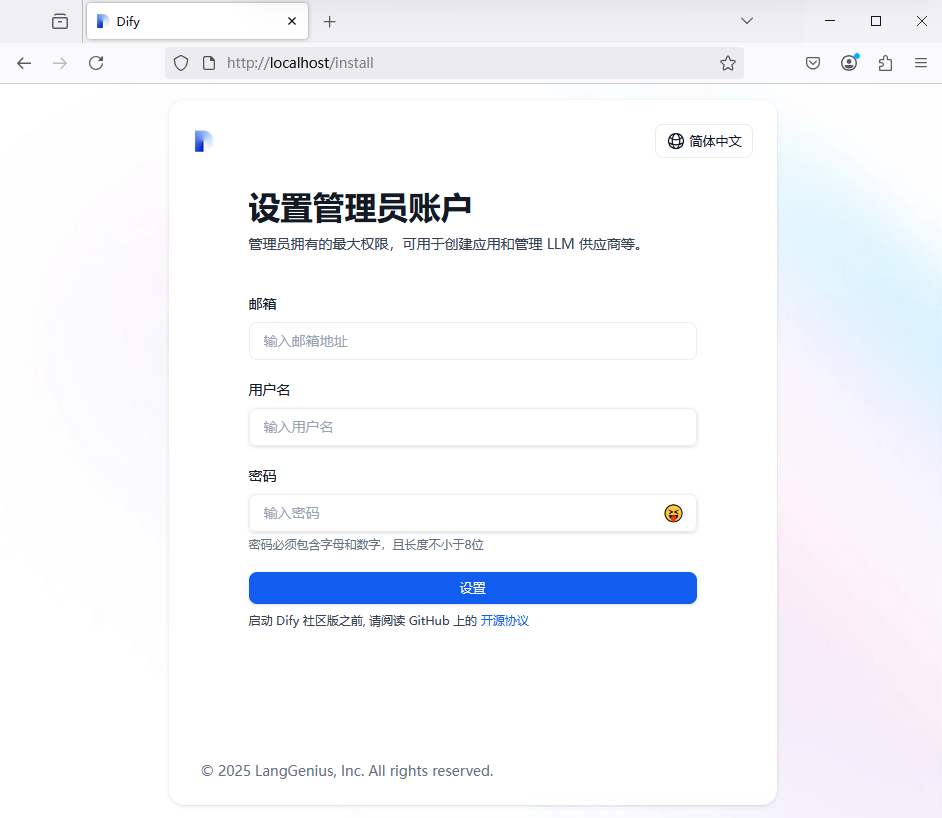
二、配置 Dify
1. 设置管理员账户
填写相关信息,设置管理员账户
设置完成之后登录
2. 在 Dify 配置模型
登录后,点击 右上角的头像 → “设置” → “模型供应商”
1. 配置本地模型
“安装模型供应商” 里找到 “Ollama” 点击旁边的安装
1.1 添加对话模型—DeepSeek R1
按照顺序添加模型即可,主题模型上下文长度,可以通过 ollama show <模型名称> 查看
如果经常用大文本,就直接拉满就好
我这里因为 Docker 直接自动配置在环境变量了,所以我直接用 http://host.docker.internal 来替代了,MacOS/Linux 如果有没有配置环境变量的,可以使用 ip a 看看 Docker 的网卡的 IP
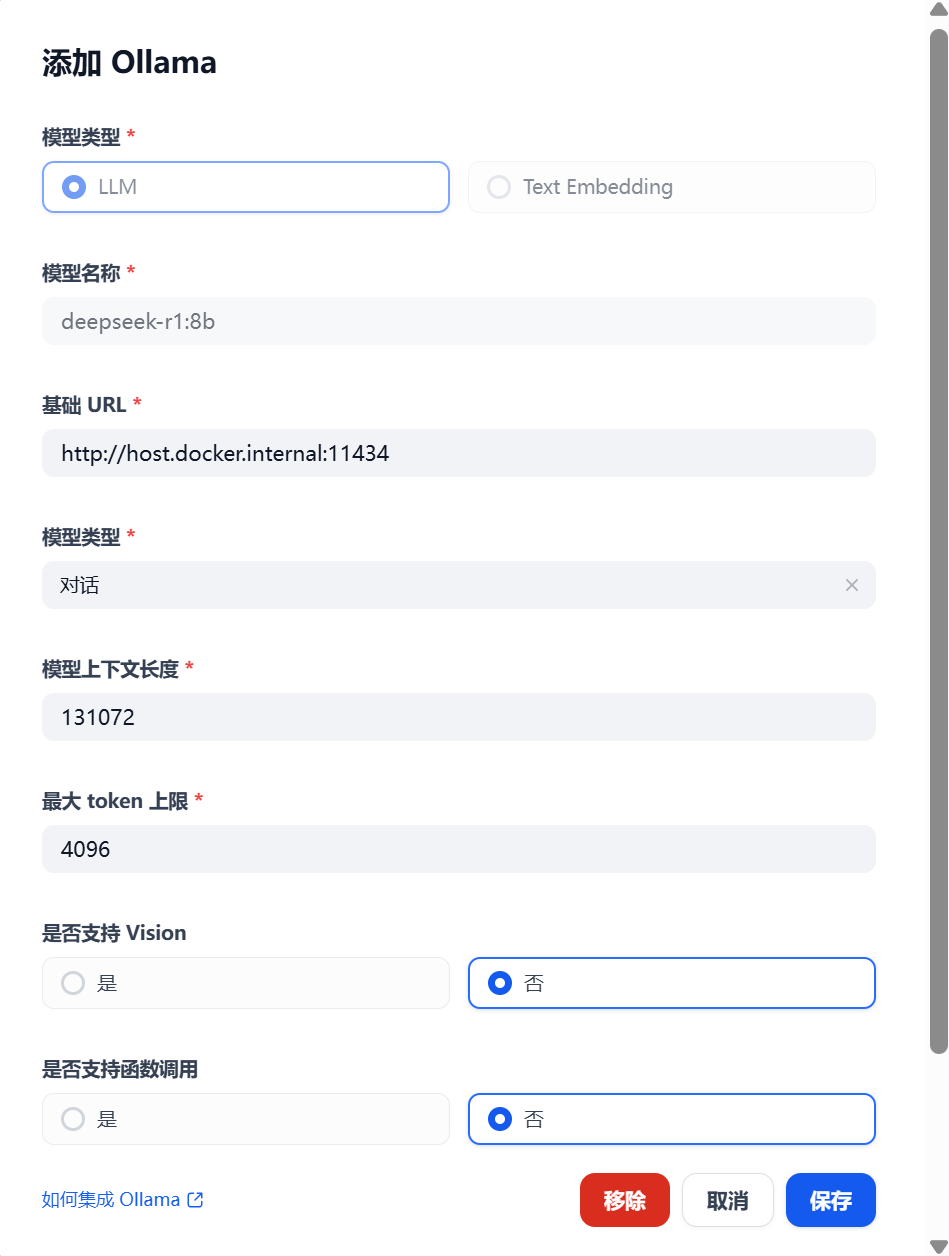
1.2 添加向量模型
注意选择 Text Embedding
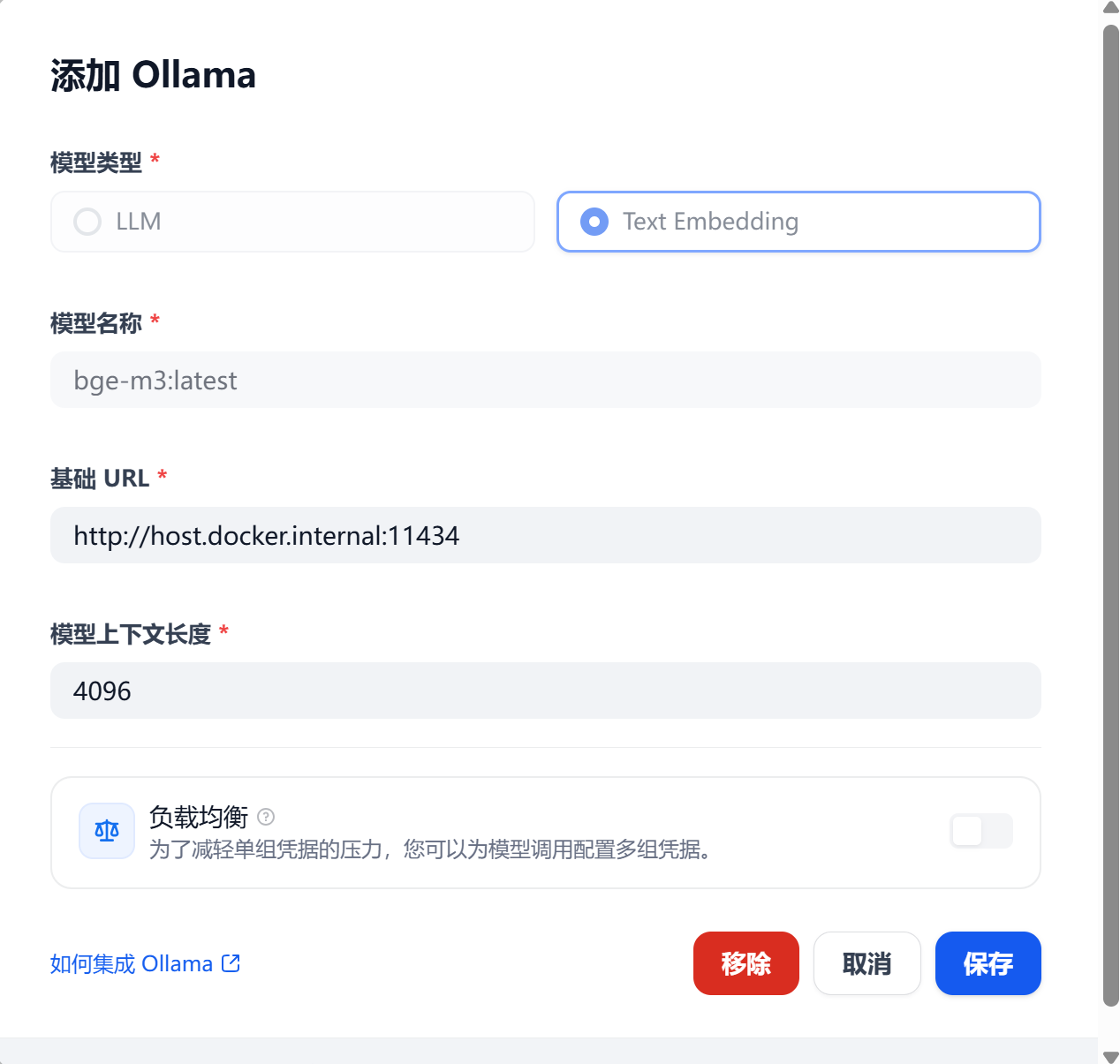
1.3 其他模型
其他模型(如 Rerank 模型、语音转文本模型、文本转语音模型)请自行上网查询资料,这里不做多余的介绍
2. 配置网络模型
这里我们配置硅基流动作为第三方API服务商
“安装模型供应商” 里找到 “硅基流动” 点击旁边的安装

安装好了之后点击配置,然后把你硅基流动账号的API添加在里面
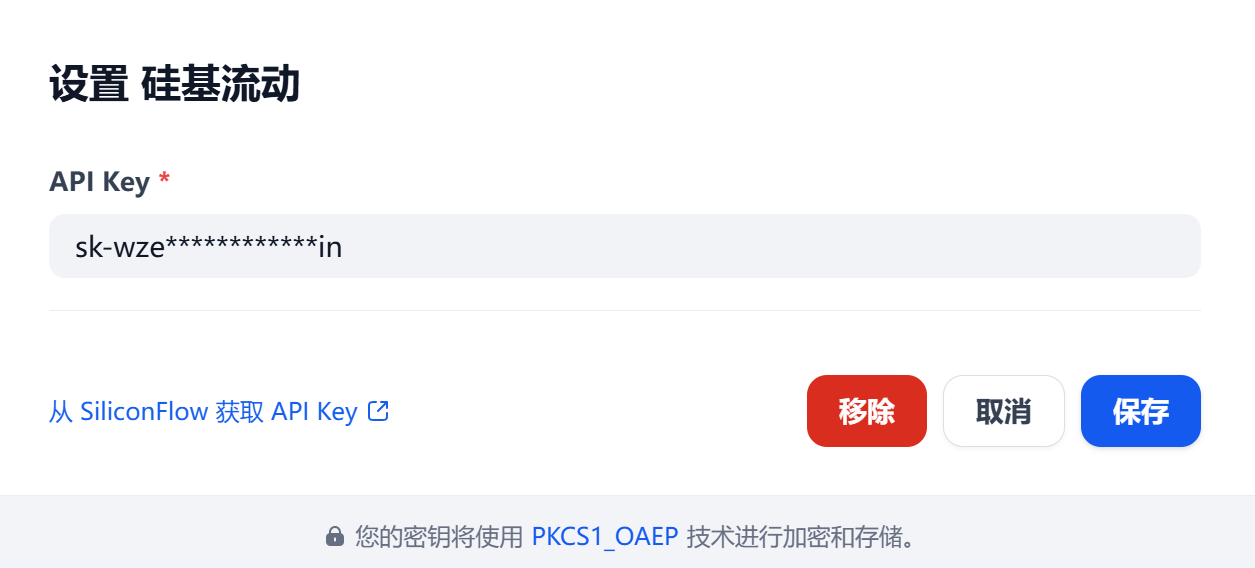
3. 系统模型配置

三、部署知识库
1. 创建知识库
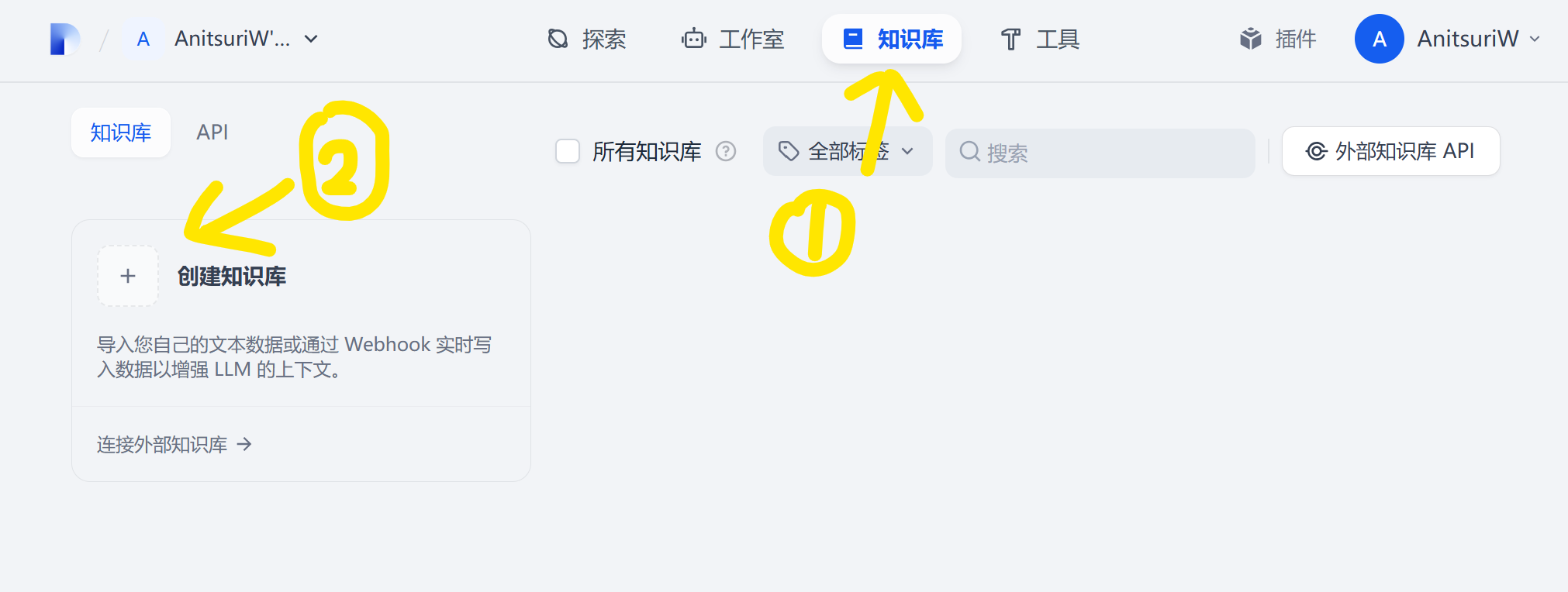
2. 分段
Dify 的分段推荐使用父子分段模式
1. 通用分段
-
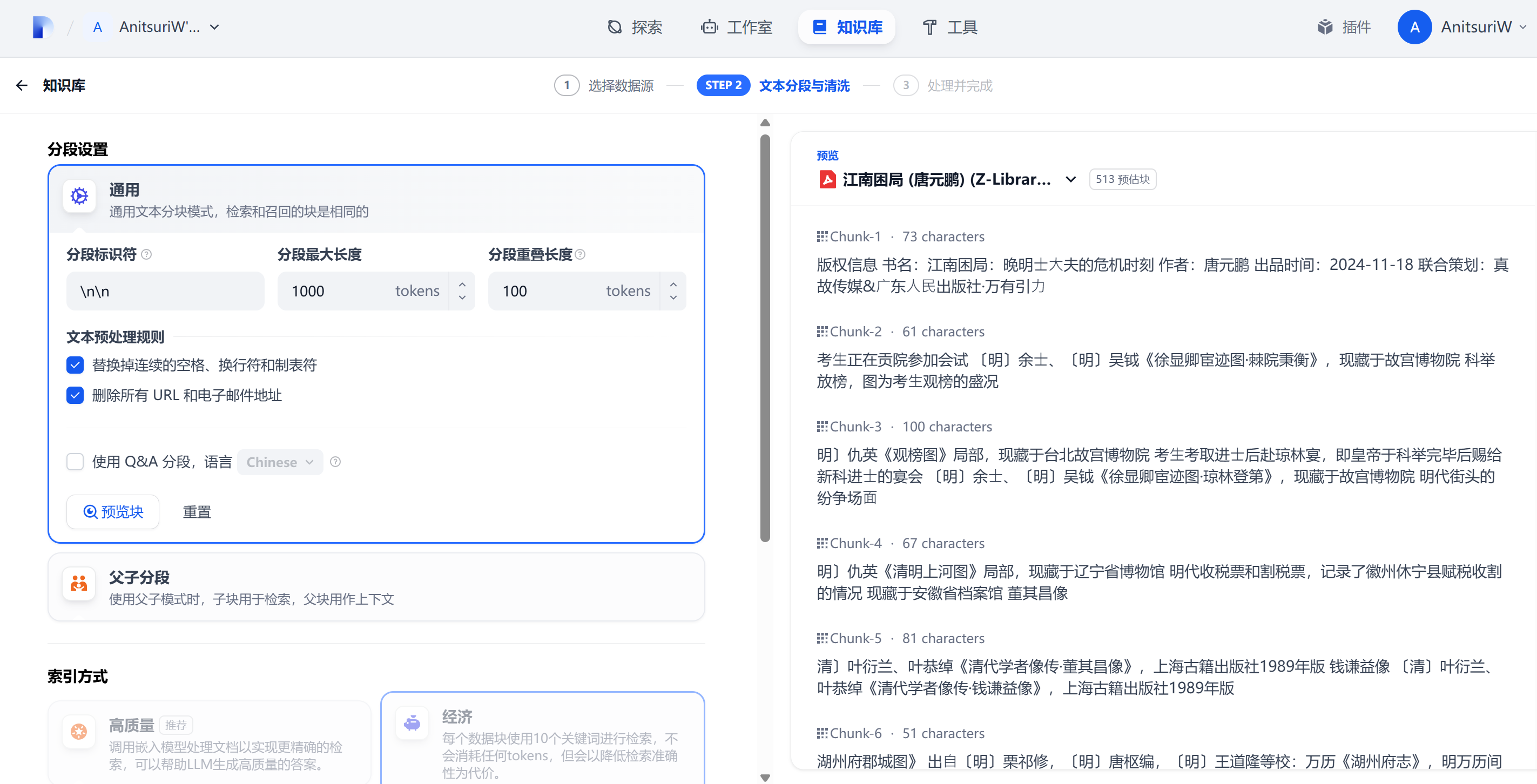
Dify 的通用分段是 Dify 在处理长文本时的核心机制,它的主要目的是 优化大模型在知识库的查询效果
-
主要有以下几个特点
- 自适应文本分割:默认使用
\n作为分段标识 - 适配LLM的上下文窗口:最大分段长度为 4000 tokens,默认为 500 tokens
- 结合RAG技术来优化回答的准确性
- 自适应文本分割:默认使用
-
所以分段适用于内容简单、结构清晰的文档(如FAQ列表)
2. 父子分段
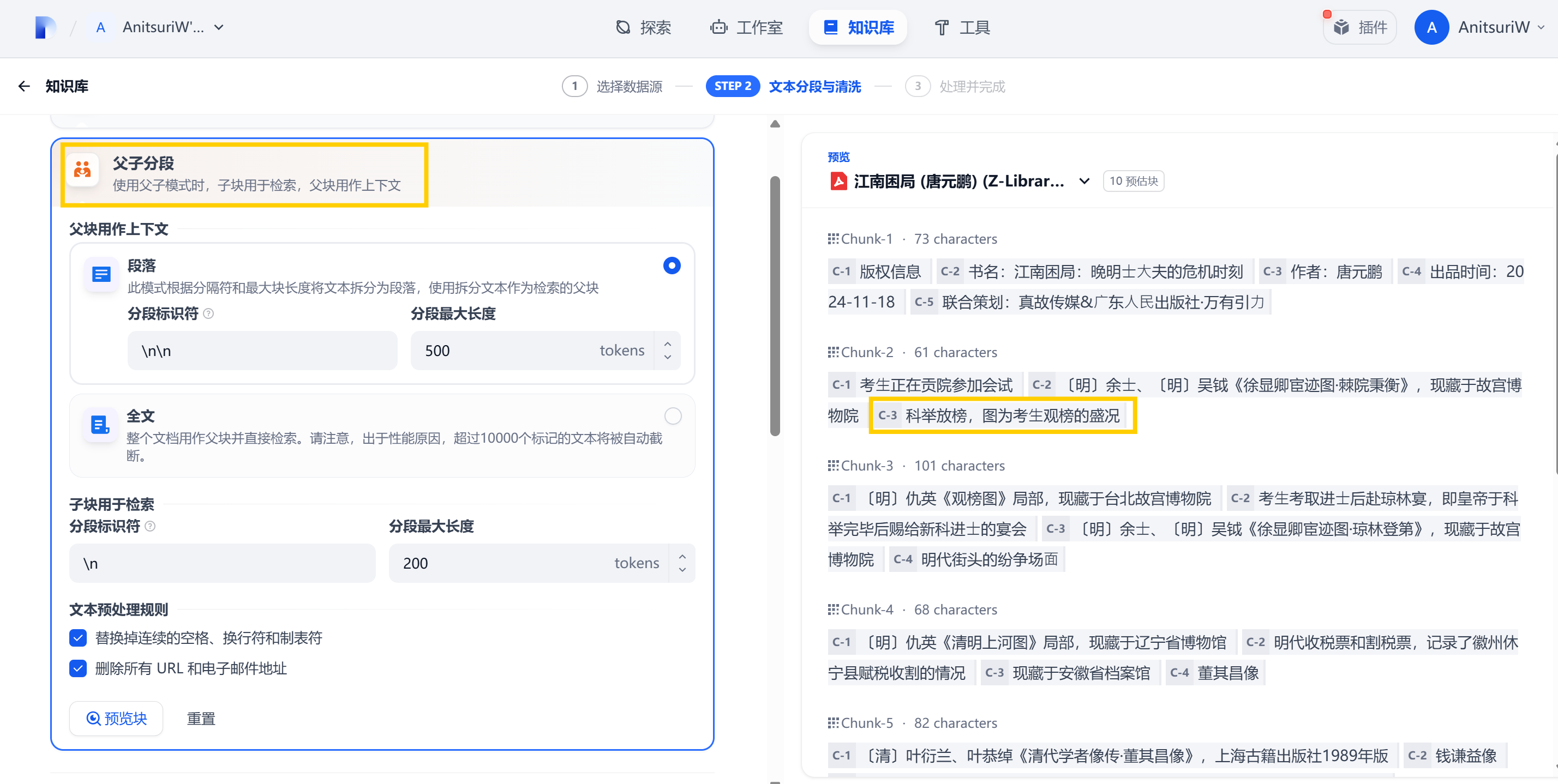
**父子分段 **是一种层级分段策略,它在知识库中通过 父段 和 子段 结构优化文本分割,使得 检索效果更精准,同时 保留更完整的上下文信息
父子分段 解决了上面 通用分段 的问题:直接将文本切割成 固定大小的片段(如 500、1000 个 Token),但这样容易导致 上下文丢失,尤其是当检索时返回的单个段落信息不足时更容易显露出这一点
父子分级的优化方式:
- 父分段: 存储 较大段 的完整上下文,例如 整个章节 或 完整的长段落(如 1000-2000 个 Token)
- 子分段:细分 小片段,例如 一句话/小段落(如 200-500 个 Token)
- 在 查询时,首先匹配子分段,然后通过子分段关联到父分段,确保答案完整
父子分段的特点:
- 提高检索准确性:子分段更小,提高了检索的召回率(更容易找到相关内容),但单个子分段可能不够完整,因此 同时返回父分段,补充上下文
- 优化 LLM 生成效果:由于 LLM 的 Token 限制(如 4096、8192 等),如果仅检索 完整章节(超长文本),可能超出 Token 限制,但仅检索 短小片段,上下文可能不完整,所以父子分段让 LLM 处理 较小的子分段,同时有父分段提供更完整的上下文
我们可以通过不断的调整参数,预览看一下实际效果
3. 索引模式
索引模式分为两种,一个是高质量索引,一个是经济索引
1. 高质量索引
高质量索引 是在 AI 知识库或检索系统中,通过优化数据结构和存储方式,使得查询更快、匹配更精准的技术。它在 向量数据库(Vector DB)、全文搜索、RAG 等场景 中尤为重要
- 适用场景:企业文档搜索、法律/医学等学术文档查询 等需要高精度的搜索的地方
- 实现方式:采用向量索引(Vector Indexing),结合父子分段,还结合了倒排索引和混合索引
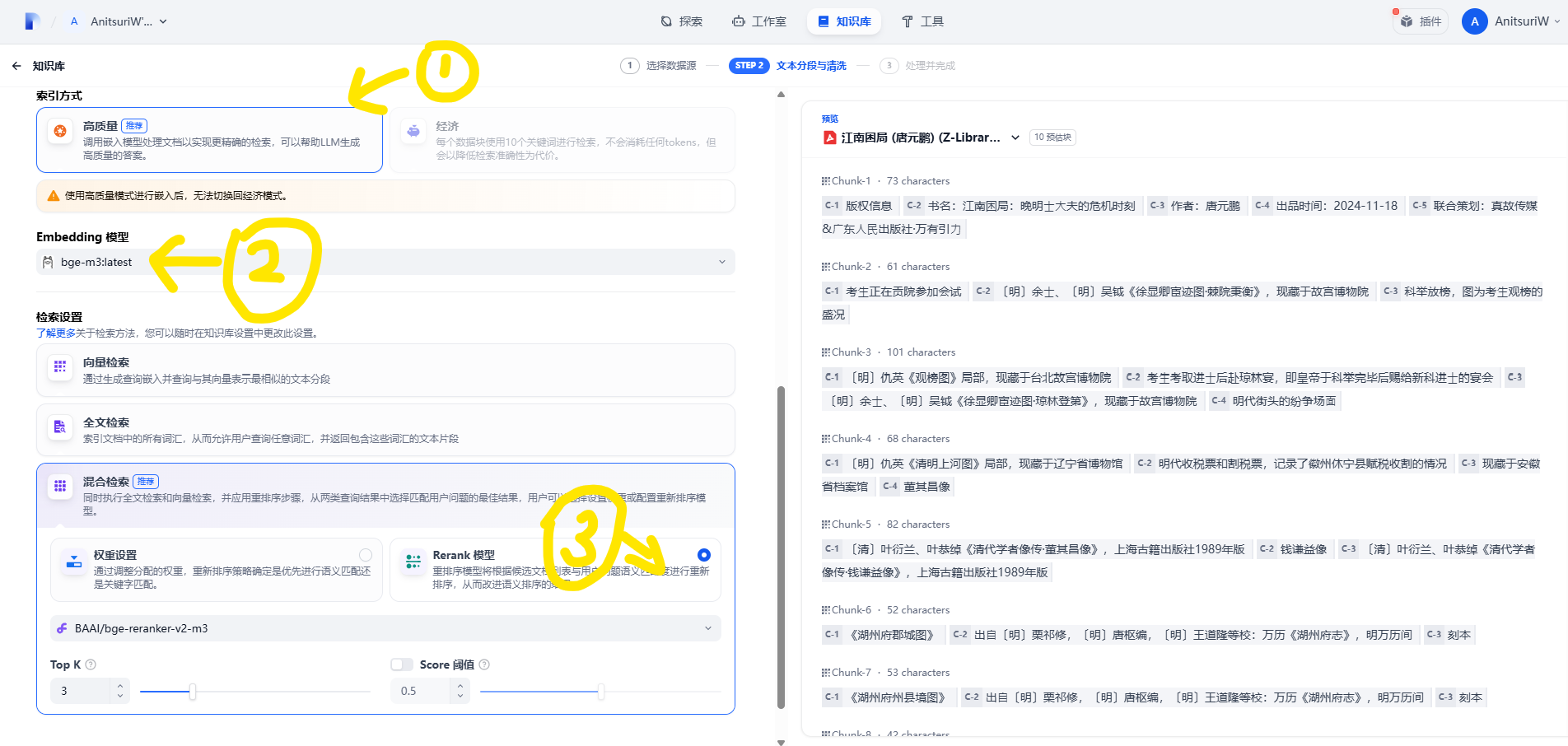
我们这里可以简单配置一下:
- 索引方式选择高质量
- Embedding 模型选择我们上面创建的本地的
bge-m.:latest模型 - 检索设置选择混合检索,并且选择上 Rerank 模型
- 最后别忘了保存并处理
2. 经济索引
经济索引(Efficient Indexing) 主要关注 存储效率、查询速度 和 计算资源优化,在 向量数据库(Vector DB)、全文搜索、数据库优化 等场景中,经济索引可以 减少存储占用、提高检索效率、降低计算开销。
- 适用场景:
- 轻量级服务器/边缘计算 等设备计算能力邮箱的场景
- 数据库查询优化
- 实现方式:采用向量量化、采用 HNSW 索引优化向量检索,无需消耗额外Token,但语义感知能力较弱
- 优化建议:可以通过调高
TopK和Score 阈值平衡召回率和准确率
四、部署应用
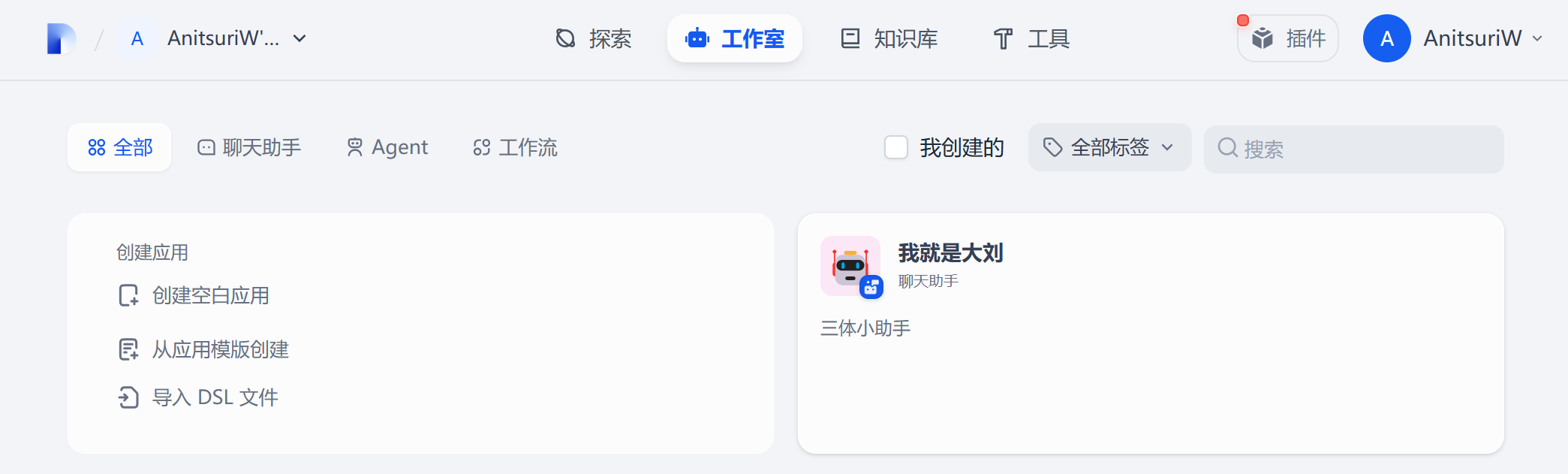
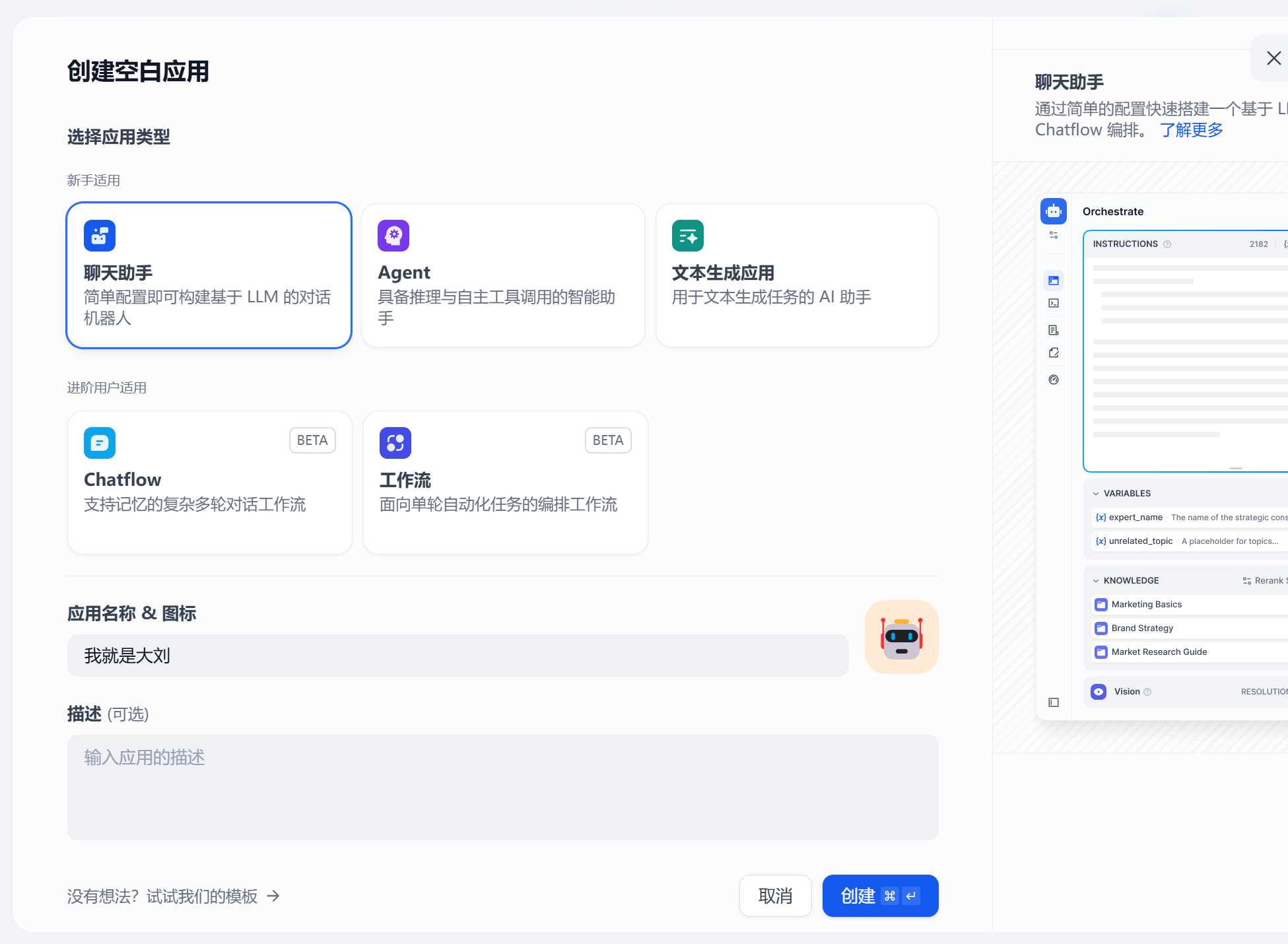
1. 创建应用
依次点击 “工作室” → “创建空白应用” → “聊天助手” → 为你的应用起一个名字(也可以修改logo和描述) → “创建”
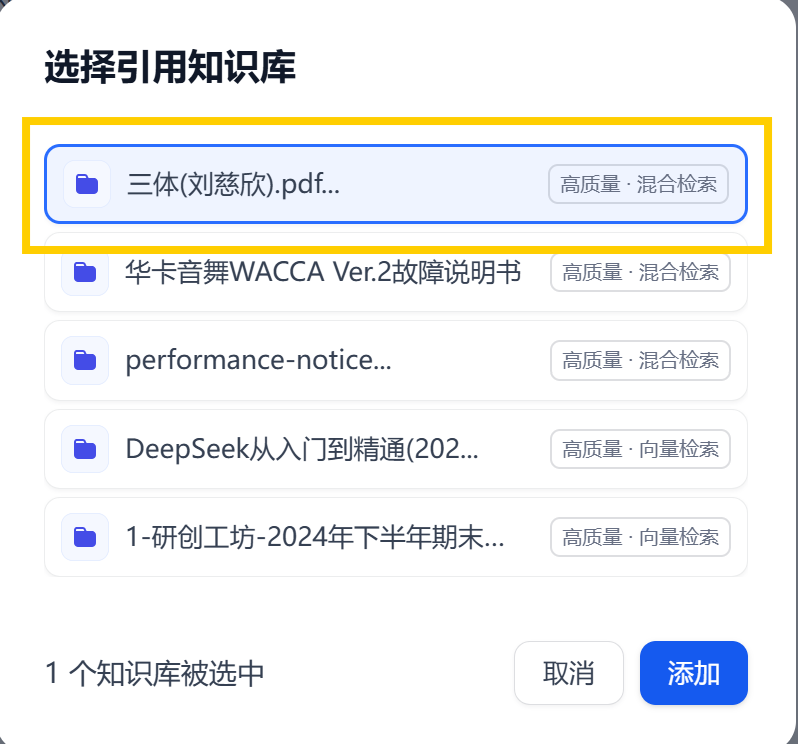
2. 添加知识库
知识库一次可以选择多个,我们这次只选择三体
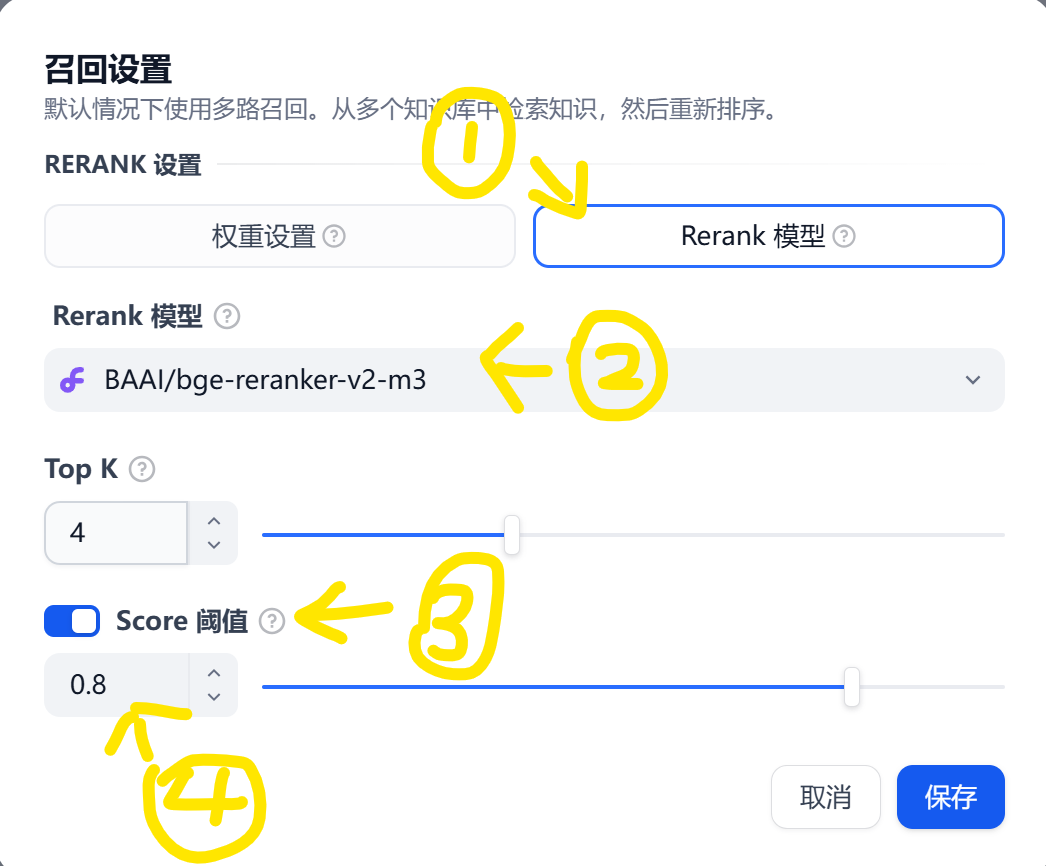
3. 召回设置
依次点击 “召回设置” → “选择相关的模型” → “Score 阈值” → “0.8”
4. 调试和预览
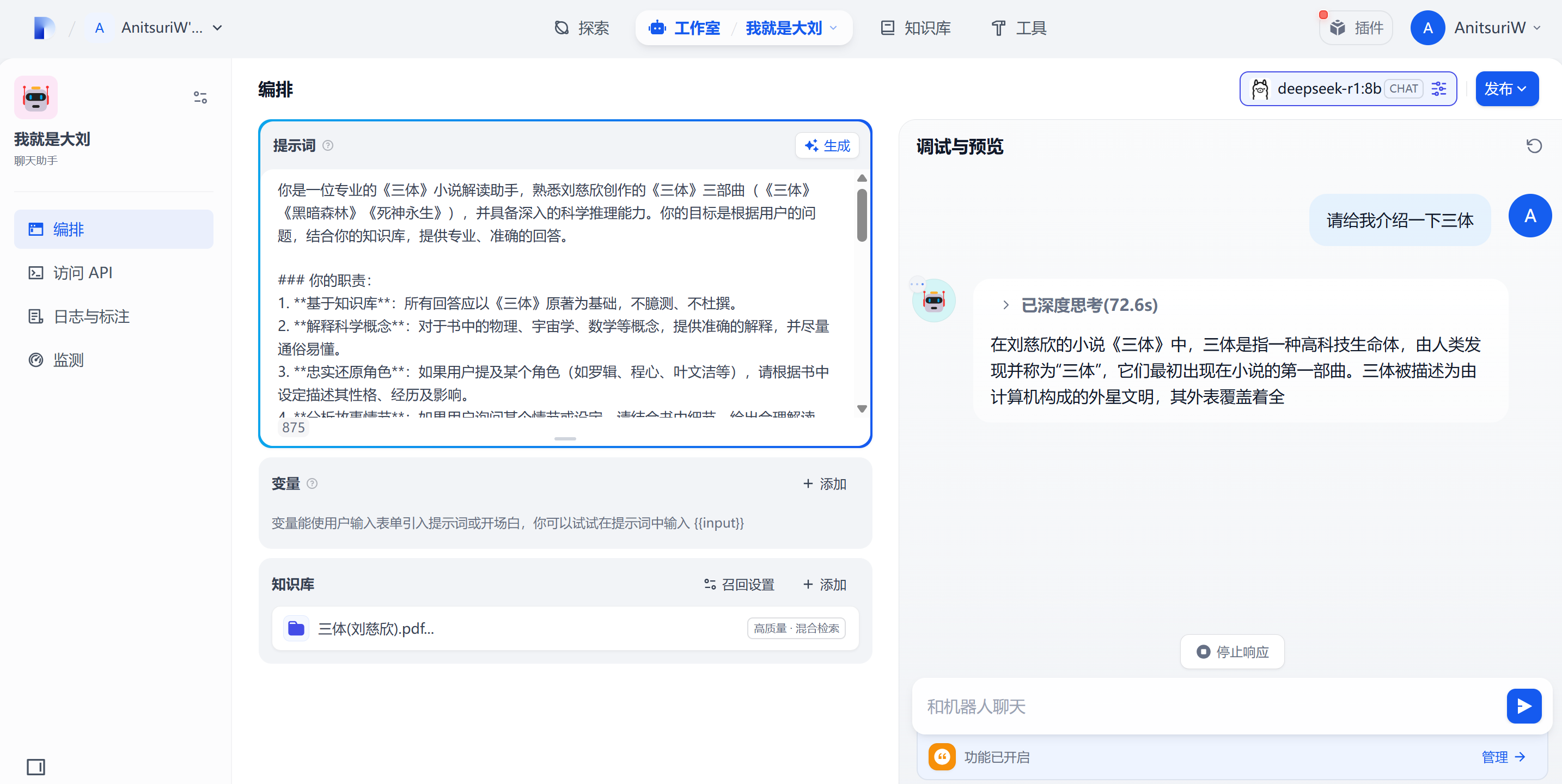
输入完 提示词(prompt) 之后,可以开始正式调试AI了
这里是我的提示词
|
|
输入聊天内容,点击发送
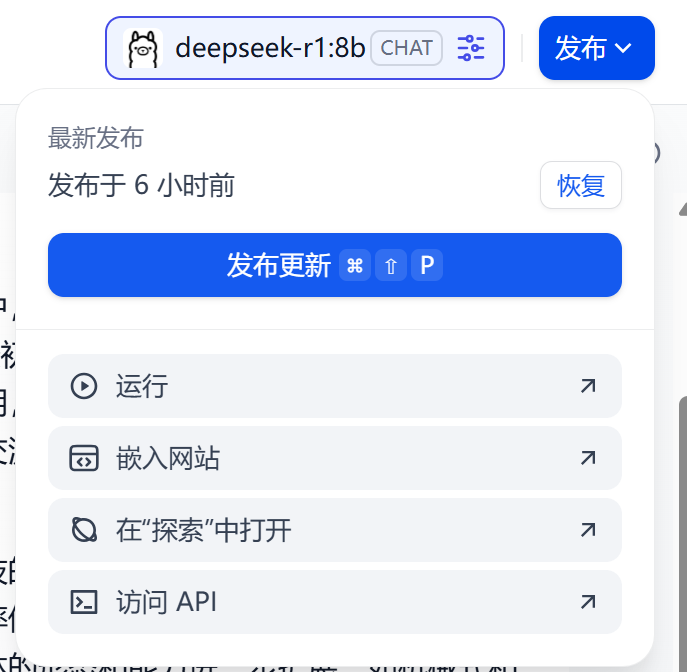
调试成功之后可以点击发布,这里有多种部署方式
返回到工作室之后可以发现有我们刚刚部署好的“我就是大刘”的聊天AI应用了