Shell 基础知识
一、Shell 介绍
Shell 是一个应用程序,是一个命令解释器,它连接了用户和 Linux 内核,让用户能够更加高效、安全、低成本地使用 Linux 内核,这就是 Shell 的本质。然而Shell本身并不是内核的一部分,它只是站在内核的基础上编写的一个应用程序,但是 Shell 也有着它的特殊性,就是开机立马启动,并呈现在用户面前;用户通过 Shell 来使用 Linux,不启动 Shell 的话,用户就没办法使用 Linux
在 CentOS 7 中,我们常用 bash 作为一种 Shell,除了 bash 一些常用的 Shell 编译器还有 zsh (zShell) 和 ksh (kShell)
Shell 也是一种脚本,是系统命令的集合,可以使用逻辑判断、循环等语法,可以自定义函数,我们编写完源码后不用编译,直接运行源码即可。
Shell 脚本是在 Linux 的 shell 中运行的,所以称为 shell 脚本。本质上,shell 脚本 就是一些命令的集合。shell 脚本 可以实现自动化运维,所以能帮助我们很方便的管理服务器;比如我们可以指定一个任务计划,定时的去执行某个 shell 脚本 已满足需求。
二、命令历史(使用过的命令)history
1. ${HISTSIZE}
这个变量设定了当前 shell 会保留多少条命令历史
当用户在命令行输入命令后,这些命令会被记录在 shell 的历史中,以便通过 history 命令查看并重复使用
历史记录数量超过 HISTSIZE 限制后,旧的命令会被删除,只保留最新的命令
2. ${HISTTIMEFORMAT}
这个变量设定显示每条命令执行的时间戳
当设置 HISTTIMEFORMAT 时,Bash 的历史记录会附加上每条命令执行的日期和时间,格式化后的时间戳会显示在 history 命令的输出中
3. chattr
这个命令用于修改 Linux 文件系统的文件属性
符号模式的格式是 +-=[aAcCdDeijsStTu]。
+ 操作符表示将选中的属性添加到文件的现有属性中;- 表示从文件中移除这些属性;= 表示文件只会拥有选定的属性。
- 设置了 ‘a’ 属性的文件只能以追加模式打开进行写入。只有超级用户或拥有
CAP_LINUX_IMMUTABLE能力的进程可以设置或清除此属性。 - 设置了 ‘d’ 属性的文件在执行
dump(8)程序时不会被备份 - 设置了 ‘i’ 属性的文件不能被修改:无法删除或重命名,也无法创建链接,无法写入数据。只有超级用户或拥有
CAP_LINUX_IMMUTABLE能力的进程可以设置或清除此属性 lsattr显示的是文件的扩展属性(也就是通过chattr编辑的属性)
| 属性标志 | 含义 |
|---|---|
| a | 只能追加(append only):文件只能以追加模式打开,不能删除或修改现有内容。 |
| A | 禁止访问时间更新(no atime updates):访问文件时不更新访问时间,减少磁盘 I/O 操作。 |
| c | 压缩(compressed):文件在磁盘上自动压缩,读取时解压缩,写入时压缩。 |
| C | 禁止写时复制(no copy on write, COW):文件不会进行写时复制操作(适用于支持 COW 的文件系统)。 |
| d | 禁止转储(no dump):设置该属性后,dump 命令不会备份该文件。 |
| D | 目录同步更新(synchronous directory updates):目录修改时同步写入磁盘。 |
| e | 扩展格式(extents):文件使用扩展格式来映射磁盘块,适用于某些文件系统。 |
| i | 不可变(immutable):文件不能被修改、删除、重命名或链接。只有超级用户或具有 CAP_LINUX_IMMUTABLE 能力的进程可以设置或清除此属性。 |
| j | 数据日志记录(data journaling):文件的数据会首先被写入日志,适用于 ext3 和 ext4 文件系统。 |
| s | 安全删除(secure deletion):文件被删除时,其数据块会被清零,确保数据无法恢复。 |
| S | 同步更新(synchronous updates):文件修改时数据同步写入磁盘,不使用缓存。 |
| t | 禁止尾部合并(no tail-merging):文件系统不会将文件末尾的部分块与其他文件合并。 |
| T | 目录层级顶部(top of directory hierarchy):表示该目录是一个目录层次结构的顶部,子目录应分散分配。 |
| u | 可恢复删除(undeletable):文件被删除后,其数据仍可恢复。 |
| E | 压缩错误(compression error):表示文件有压缩错误(只读,无法使用 chattr 设置或修改)。 |
| h | 超大文件(huge file):文件大小大于 2TB(只读,无法使用 chattr 设置或修改)。 |
| I | 索引目录(indexed directory):目录使用哈希树进行索引(只读,无法使用 chattr 设置或修改)。 |
| N | 内联数据(inline data):文件的数据存储在 inode 中(只读,无法使用 chattr 设置或修改)。 |
| X | 压缩原始访问(compression raw access):允许直接访问压缩文件的原始内容(只读,无法使用 chattr 设置或修改)。 |
| Z | 压缩脏文件(compressed dirty file):表示文件已被压缩但数据尚未完全写入磁盘(只读,无法使用 chattr 设置或修改)。 |
4. !!
这个命令是打印上一条命令并把它执行出来
5. !(数字)
这个命令是打印 history 里面的 第 (数字) 条命令并把它执行出来
6. !<命令>
这个命令是打印 history 里面 最近的一个 以 <命令> 为开头的命令并把它执行出来
三、命令补全和别名
1. 命令补全
需要用到额外软件包
bash-completion
- 补全命令: 如果你输入命令的一部分,可以按下
Tab键让 Bash 自动完成命令 - 补全命令选项: 输入一个命令后,可以通过
Tab自动补全该命令的选项 - 补全路径和文件名: 在输入命令时,使用
Tab补全路径和文件名 - 补全环境变量: 在输入
$后按Tab键可以自动补全环境变量
2. alias(别名)
2.1 创建别名
$ alias 别名='命令'2.2 查看别名
$ alias2.3 查看单个别名
$ alias 别名2.4 取消别名Z
$ unalias 别名四、通配符 输入输出重定向
1. 通配符
?
[ ] 这个也可以做判断
{ }
2. 输入输出重定向
>
>>
2>
2>>
&> 正确和错误重定向
&>>
五、命令
1. cut
cut 命令用于从文本中提取特定的列或字段
-d <分隔符>:指定字段分隔符(默认为制表符)-f <字段号>:选择要显示的字段(用逗号或连字符分隔的列表)
假如
file.txt的内容如下
$ cut -d ',' -f 1,3 file.txt # 提取以逗号分隔的第1和第3个字段
name,cityAlice,New YorkBob,San FranciscoCharlie,Los Angeles-c <字符范围>:基于字符位置提取
$ cut -c 1-5 file.txt # 提取每行的第1到5个字符
name,AliceBob,3Charl--complement:补集选择,即不显示指定的字段或字符范围
$ cut --complement -d ',' -f 2 file.txt # 从上面的 file.txt 文件中排除第 2 个字段
name,cityAlice,New YorkBob,San FranciscoCharlie,Los Angeles就等同于 cut -d ',' -f 1,3 file.txt
2. sort
sort 命令用于对文件按字典顺序(ASCII 码顺序)进行排序,支持数字、字母顺序的升序或降序排列
假设有一个
names.txt内容如下
- 什么都不加默认是升序排序
$ sort names.txt
AliceBobCharlieDavid-r:降序排列
$ sort -r names.txt
DavidCharlieBobAlice-n:按数值进行排序
假设有一个
numbers.txt文件,内容如下
$ sort -n numbers.txt
23050100-k <字段>:指定按第几列排序
假设有一个
students.txt文件,内容如下Terminal window
# 我们希望按 分数(第二列) 进行排序,而不是按 名字(第一列) 排序$ sort -k 2 students.txt
David 80Bob 85Alice 90Charlie 95-t <分隔符>:指定分隔符(默认是空格)
假设有一个
data.csv文件,内容如下Terminal window
# 我们希望按 第二列(分数) 进行排序$ sort -t ',' -k 2 -n data.csv
David,80Bob,85Alice,90Charlie,95-u:排序后删除重复行-o:将结果保存到文件
$ sort names.txt -o sorted_names.txt3. wc
wc (word count) 命令用于统计文件中的行数、单词数、字节数或字符数
-l:只显示行数-w:显示单词数-c:显示字节数-m:显示字符数-L:显示最长行的长度(字符数)
4. uniq
假设有一个
names.txt文件,内容如下Terminal window
# uniq 只能过滤相邻的重复行,因此我们需要先对文件进行排序$ sort names.txt | uniq
AliceBobCharlieDavid-c:显示每行出现的次数
$ sort names.txt | uniq -c
2 Alice 2 Bob 1 Charlie 1 David-d:只显示重复的行
$ sort names.txt | uniq -d
AliceBob-u:只显示不重复的行
$ sort names.txt | uniq -u
CharlieDavid-i:忽略大小写
假设有一个
names_case.txt文件,内容如下Terminal window
$ sort names_case.txt | uniq -i
AliceBobCharlie-f <n>:忽略前 n 个字段
假设有一个
students.txt文件,内容如下Terminal window
$ sort students.txt | uniq -f 1
Alice 85Charlie 95David 80Bob 905. tee
-a:将内容追加到文件,而不是覆盖
$ ls | tee output.txt # 将 ls 输出保存到 output.txt 并显示在终端$ ls | tee -a output.txt # 追加输出到 output.txt--ignore-interrupts:忽略中断信号(如Ctrl+C)
6. tr
tr 命令用于转换或删除文本中的字符。常用于大小写转换、删除特定字符等
tr 'set1' 'set2':将set1中的字符替换为set2中对应的字符-d:删除指定字符-s:将重复出现的字符压缩为单个
7. split
split 命令用于将大文件分割成多个小文件。可以按行数或文件大小进行分割
-l <行数>:按每个文件的行数进行分割-b <字节大小>:按字节数进行分割-d:使用数字后缀(默认为字母后缀)-a <后缀长度>:指定分割文件后缀的长度
$ split -l 100 file.txt part_ # 每100行分割成一个文件,文件前缀为 part_$ split -b 1M file.txt part_ # 每1MB 分割一个文件$ split -l 100 -d file.txt part_ # 使用数字后缀六、Shell 脚本
1. Shell 脚本结构与执行
1.1 脚本结构
第一行一定得是 #!/bin/bash 。该命令说明,该文件使用的是 bash 语法,如果不设置改行,则该脚本不会被执行。以 # 开头的行作为解释说明。Shell 脚本 通常以 sh 为后缀,用于区分这是一个 Shell 脚本。
下面我们来编写一个 shell 脚本,如下所示:
$ mkdir shell$ cd shell$ vi 1.sh# 然后写入以下内容
#!/bin/bashtouch /tmp/1.txtchmod 600 /tmp/2.txtmv /tmp/1.txt /tmp/2.txt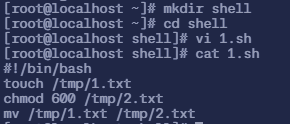
1.2 脚本执行
接下来我们执行刚才编写的脚本
$ bash 1.sh 其实 shell 脚本 还有一种执行方法,但前提是脚本本身要有执行权限,所以执行前我们需要给脚本加一个 x 权限
$ ./1.sh-bash: ./1.sh: 权限不够$ chmod +x 1.sh$ ./1.sh
2. 常用命令
2.1 查看脚本执行过程
$ bash -x 1.sh+ touch /tmp/1.txt+ chmod 600 /tmp/2.txt+ mv /tmp/1.txt /tmp/2.txt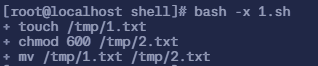
2.2 查看脚本是否有语法错误
$ bash -n 1.sh2.3 date 命令
2.3.1 显示 年 月 日
date +%Y-%m-%d #年(四位)月日date +%y-%m-%d #年(两位)月日date +%F #年(四位)月日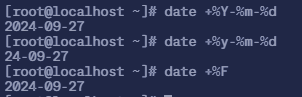
2.3.2 显示 小时 分钟 秒
date +%H:%M:%Sdate +%T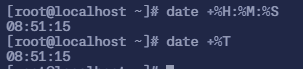
2.3.3 显示星期
date +%w #一周中的第X天date +%W #一年中的第X周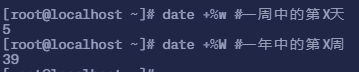
2.3.4 时间戳
时间戳是指特定时间的标识,通常以数字形式表示,表示自某个特定时刻以来经过的时间。时间戳广泛用于计算机系统、数据库和网络应用中,以记录事件的发生时间或用于时间相关的计算
这里使用的是 Unix 时间戳
Unix 时间戳:自 1970 年 1 月 1 日(UTC)以来经过的秒数。例如,Unix 时间戳 1633072800 表示 2021 年 10 月 1 日,要是看现在的就用下面的命令
date +%s 使用下面的命令显示输入秒数之前的时间
date -d @1633072800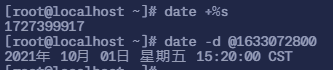
2.3.5 显示一个小时之前/之后
date -d "+1 hour" #1h之后date -d "-1 hour" #1h之前
2.3.6 显示一天之前/之后
date -d "+1 day" #一天后date -d "-1 day" #一天前
3. shell 脚本中的变量
在 shell 脚本 中使用变量可以节省时间并且使我们的脚本更加专业,所以当我们编写一个脚本时,就可以使用变量来代替某个使用频繁并且长度很长的字符串。变量的格式:“变量名=变量的值”
3.1 引用命令的结果
当我们引用某个命令的结果时,可以使用变量代替
$ a=`date +%w`$ echo $a6$ a=$(date +%w)$ echo $a6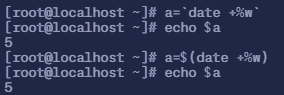
3.2 与用户交互
$ read -p "请输入一个数字:" n请输入一个数字:10$ echo $n10$ read -p "请输入一个数字:"请输入一个数字:2005$ echo $REPLY2005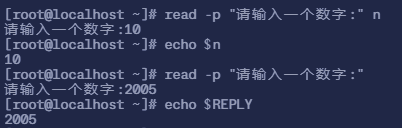
3.3 内置变量
$ vi bian.sh #创建一个名为 bian.sh 的脚本# 填入以下内容
#!/bin/bashecho "\$1=$1"echo "第二个参数是$2"echo "第三个参数是$3"echo "本脚本一共有$#个参数"echo "\$0是$0"# 执行脚本$ sh bian.sh
$1=第二个参数是第三个参数是本脚本一共有0个参数$0是bian.sh
# 再次执行脚本$ sh bian.sh a b c$1=a第二个参数是b第三个参数是c本脚本一共有3个参数$0是bian.sh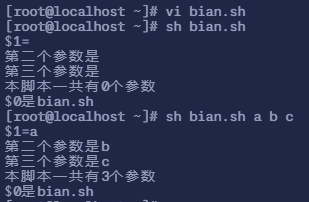
3.4 数学运算
$ vi sum.sh# 填入以下内容
#!/bin/basha=1b=2sum=$[$a+$b]echo "$a+$b=$sum"# 执行脚本$ sh sum.sh1+2=3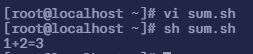
4. Shell 中的逻辑判断
4.1 不带有 else
基础结构
if [判断语句] then commandfi example
$ vi if1.sh# 填入以下内容
#!/bin/bash
a=10if [ $a -gt 4 ]thenecho okfi# 执行脚本$ sh -x if1.sh+ a=10+ '[' 10 -gt 4 ']'+ echo okok
# 检验语法错误$ sh -n if1.sh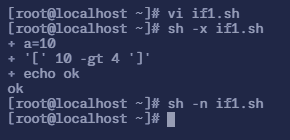
4.2 带有 else
基础结构
if [判断语句] then commandelse commandfi exapmle
$ vi if2.sh# 填入以下内容
#!/bin/bash
a=10if [ $a -gt 4 ] then echo ok else echo "not ok"# 执行脚本$ sh -x if1.shsh -x if1.sh+ a=10+ '[' 10 -gt 4 ']'+ echo okok
# 检验脚本语法$ sh -n if1.sh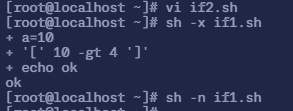
4.3 带有 elif
$ vi if3.sh# 填入以下内容
#!/bin/basha=3if [ $a -gt 4 ] then echo ok elif [ $a -gt 8 ] then echo "very ok" else echo "not ok"fi# 执行脚本$ sh -x if3.sh+ a=3+ '[' 3 -gt 4 ']'+ '[' 3 -gt 8 ']'+ echo 'not ok'not ok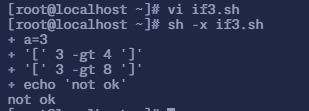
4.4 嵌套
$ vi if4.sh# 填入以下内容
#!/bin/bash
a=10if [ $a -gt 4 ]then if [ $a -lt 20 ] then echo "ok" else echo "very ok" fielse echo "not ok"fi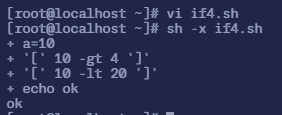
4.5 多个条件
if [ $a -gt 5 ] && [ $a -lt 10 ] == if [ $a -gt 5 -a $a -lt 10] # -a表示 andif [ $b -gt 5 ] || [ $b -lt 3] == if [ $b -gt 5 -o $b -lt 3 ] # -o表示 or4.6 if 逻辑判断
4.6.1 if 判断文件的目录属性
shell 脚本 中 if 经常用于判断文档的属性,比如判断是普通文件还是目录,判断文件是否有读、写、执行权限等。if 常用选项如下:
-e:判断文件或目录是否存在。-d:判断是不是目录以及是否存在。-f:判断是不是普通文件以及是否存在。-T:判断是否有读权限。-w:判断是否有写权限。-X:判断是否可执行。
*注:root用户对文件的读写比较特殊,即使一个文件没有给root用户读或者写的权限,root也可以读或者写
4.6.2 if 判断的一些特殊用法
命令
if [ -z "$a" ];表示当变量 a 的值为空时会怎么样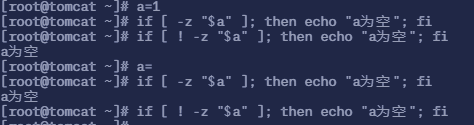
命令
if [ -n "$a" ];表示当变量 a 的值不为空时会怎么样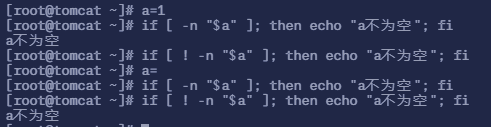
命令
if grep -q '123' 1.sh; then表示如果 1.sh 中含有 ‘123’ 会怎么样,其中-q表示即使过滤内容也不要打印出来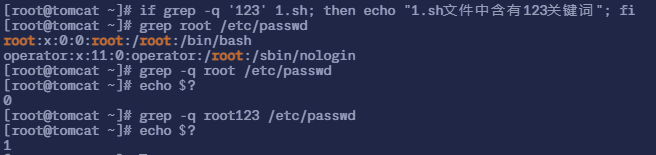
if (($a<1)); then等同于if [ $a -lt 1 ]; then,二者都可以用来进行判断,需要注意的是,当我们未对变量 a 进行赋值时则会报错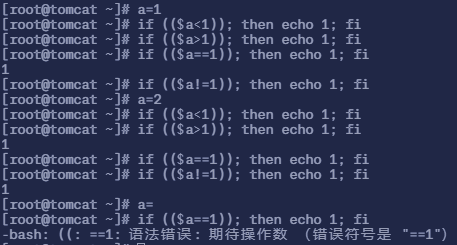
- 注意:
[ ]中不能使用<,>,==,!=,>=,<=这样的符号,需要时要使用固定写法-gt (>);-lt(<);-ge(>=);-le(<=);-eq(==);-ne(!=)
- 注意:
4.7 shell 中的 case 判断
case 判断的基础格式
case 变量 invalue1) command ;;value2) command ;;*) command ;;esac 为了让我们能够更加清晰的理解 case 逻辑判断,接下来我们编写一个脚本来进行实验
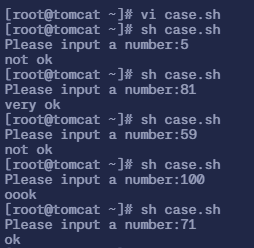
$ vi case.sh# 填入以下内容
#!/bin/bashread -p "Please input a number:" nif [ -z "$n" ]then echo "Please input a number." exit 1fi
n1=`echo $n|sed 's/[0-9]//g'`if [ -n "$n1" ]then echo "Please input a number." exit 1fi
if [ $n -lt 60 ] && [ $n -ge 0 ] # 条件是 0 <= n < 60then tag=1elif [ $n -ge 60 ] && [ $n -lt 80 ] # 条件是 60 <= n < 80then tag=2elif [ $n -ge 80 ] && [ $n -lt 90 ] # 条件是 80 <= n < 90then tag=3elif [ $n -ge 90 ] && [ $n -le 100 ] # 条件是 90 <= n <= 100then tag=4else tag=0ficase $tag in 1) echo "not ok" ;; 2) echo "ok" ;; 3) echo "very ok" ;; 4) echo "oook" ;; *) echo "The number range is 0-100." ;;esac- 这段的意思是:接收用户输入的一个数字,并根据该数字的范围(0-100),输出相应的评价信息,如 “not ok”、“ok”、“very ok” 或 “oook”,如果输入超出范围或不是数字,则提示错误
5. shell 中的循环
5.1 for 循环
基础结构如下
for 变量名 in 循环条件;do commanddone 下面进行一个简单的演示
$ vi for1.sh# 填入以下内容
#!/bin/bashsum=0for i in `seq 1 10`do sum=$[$sum+$i] echo $idoneecho $sum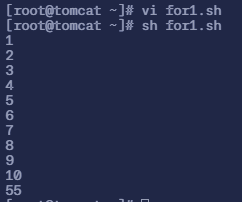
5.2 while 循环
基础结构
while 条件do commanddone example 1
$ vi while2.sh# 填入以下内容
#!/bin/bashwhile :do read -p "Please input a number: " n if [ -z "$n" ] then echo "you need input sth." continue fi n1=`echo $n|sed 's/[0-9]//g '` if [ -n "$n1" ] then echo "you just only input numbers." continue fi breakdoneecho $n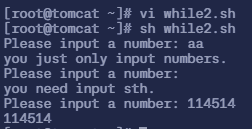
6. Shell 中的中断与继续
6.1 跳出循环
break 在脚本中表设计跳出该层循环
$ vi break1.sh# 填入以下内容
#!/bin/bashfor i in `seq 1 5`do echo $i if [ $i -eq 3 ] then break fi echo $idoneecho aaaaa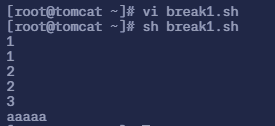
6.2 结束本次循环
当在 shell 脚本中使用 continue 时,结束的不是整个循环,而是本次循环。忽略 continue 之下的代码,直接进行下一次循环
$ vi continue1.sh# 填入以下内容
#!/bin/bashfor i in `seq 1 5`do echo $i if [ $i == 3 ] then continue ##此处continue表示若 $i == 3 则结束本次循环 fi echo $idoneecho $i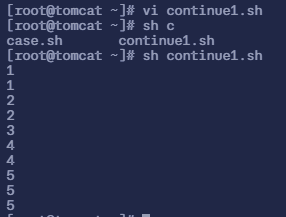
6.3 退出整个脚本
当我们在 shell 脚本中遇到 exit 是,其表示直接退出整个 shell 脚本
$ vi exit1.sh# 填入以下内容
#!/bin/bashfor i in `seq 1 5`do echo $i if [ $i == 3 ] then exit fi echo $idoneecho aaaa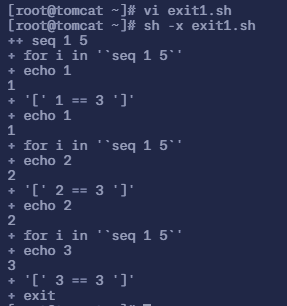
7. Shell 中的函数
shell 脚本 中的函数就是先把一段代码整理到了一个小单元中,并给这个小单元命名,当我们用到这段代码时直接调用这个小单元的名字就可以了,这样很方便,省时省力。但我们需要注意,在 shell 脚本 中,函数一定要写在前面,因为函数要被调用的,如果还未出现就被调用就会出错。
基础格式
function f_name(){ command}- 解释:
function是定义一个函数的关键字,但在大多数现代 Shell(如 Bash)中,function关键字是可选的f_name是函数的名称(你可以自定义这个名字),它可以是任何合法的函数名{}大括号包围的是函数体,里面的command表示函数中要执行的命令
7.1 打印出第一个、第二个参数、参数的个数及脚本名
$ vi fun1.sh# 填入以下内容
#!/bin/bashinput(){ echo $1 $2 $# $0 # 函数的参数:$1 $2 $# ;$0则是脚本的名字}input 1 a b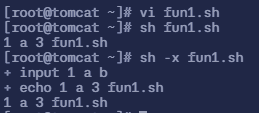
7.2 加法的函数
$ vi fun2.sh# 填入以下内容
#!/bin/bashsum(){ s=$[$1+$2] echo $s}sum 1 2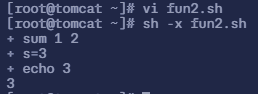
7.3 获得一个网卡的 IP 地址
$ vi fun3.sh# 填入以下内容
#!/bin/baship(){ ifconfig | grep -A1 "$1: " | tail -1 | awk '{print $2}'}read -p "Please input the eth name:" emyip=`ip $e`echo "$e address is $myip"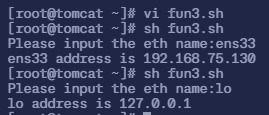
8. shell 中的数组
8.1 数组读取
首先我们需要先定义一个数组 a=(1 2 3 4 5)
命令
echo ${a[@]}读取数组中的全部元素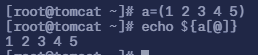
命令
echo ${#a[@]}获取数组的元素个数
命令
echo ${a[2]}读取第三个元素,数组从 0 开始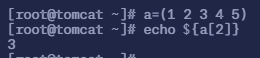
命令
echo ${a[*]}等同于echo ${a[@]}作用为显示整个数组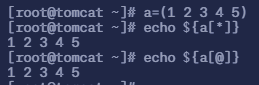
8.2 数组赋值
a[1]=100; echo ${a[@]}替换指定元素值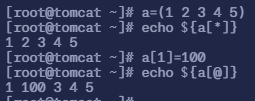
a[5]=2; echo ${a[@]}如果下标不存在则会自动添加一个元素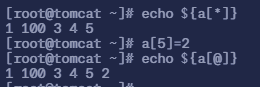
a[7]=6; echo ${a[@]}跳着添加元素时,中间未赋值的元素,不显示且无值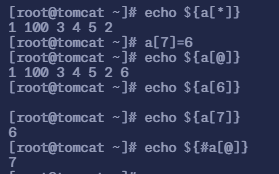
8.3 数组的删除
命令
unset a[1]用于删除单个元素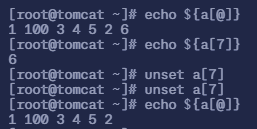
命令
unset a用于删除整个数组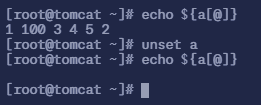
8.4 数组分片
在进行实验操作之前,需要对一个数组进行赋值 a=($(seq 1 5))
命令
echo ${a[@]:0:3}表示从第一个元素开始,截取 3 个元素,并打印出来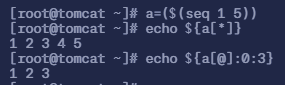
命令
echo ${a[@]:1:4}表示从第二个元素开始,截取 4 个元素,并打印出来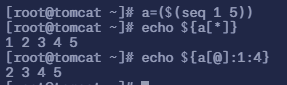
命令
echo ${a[@]:0-3:2}表示从倒数第 3 个元素开始,截取 2 个元素,并打印出来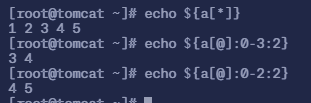
8.5 数组替换
命令
echo ${a[@]/b/100}表示用 100 替换 b,但不会保存替换,只是打印出来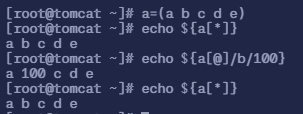
命令
a=(${a[@]/b/100})表示用 100 替换 b,这种方法不仅可以打印出来,还可以保存替换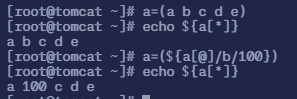
七、正则表达式
1. grep/egrep 工具的使用
该命令的格式为 grep [-cinvABC] 'word' filename
-c:表示打印符合要求的行数-i:表示忽略大小写-n:表示输出符合要求的行及其行号-v:表示打印不符合要求的行-A:后面跟一个数字(有无空格都行),eg:-A2表示打印符合要求的行以及下面两行-B:后面跟一个数字,eg:-B2表示打印符合要求的行以及上面两行-C:后面跟一个数字,eg:-C2表示打印符合要求的行以及上下各两行
eg:
过滤出带有某个关键词的行,并输出行号
Terminal window $ grep -n 'root' /etc/passwd1:root:x:0:0:root:/root:/bin/bash10:operator:x:11:0:operator:/root:/sbin/nologin过滤出不带有某个关键词的行,并输出行号
Terminal window $ grep -nv 'nologin' /etc/passwd1:root:x:0:0:root:/root:/bin/bash6:sync:x:5:0:sync:/sbin:/bin/sync7:shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown8:halt:x:7:0:halt:/sbin:/sbin/halt过滤出所有包含数字的行
Terminal window $ grep '[0-9]' /etc/inittab# multi-user.target: analogous to runlevel 3# graphical.target: analogous to runlevel 5过滤出所有不包含数字的行
Terminal window $ grep -v '[0-9]' /etc/inittab# inittab is no longer used when using systemd.## ADDING CONFIGURATION HERE WILL HAVE NO EFFECT ON YOUR SYSTEM.## Ctrl-Alt-Delete is handled by /usr/lib/systemd/system/ctrl-alt-del.target## systemd uses 'targets' instead of runlevels. By default, there are two main targets:### To view current default target, run:# systemctl get-default## To set a default target, run:# systemctl set-default TARGET.target#过滤掉所有以
#开头的行 在正则表达式中,
^表示行的开始Terminal window $ grep -v '^#' /etc/vsftpd/vsftpd.confanonymous_enable=YESlocal_enable=YESwrite_enable=YESlocal_umask=022dirmessage_enable=YESxferlog_enable=YESconnect_from_port_20=YESxferlog_std_format=YESlisten=NOlisten_ipv6=YESpam_service_name=vsftpduserlist_enable=YEStcp_wrappers=YES- PS:这里面是有空行的
过滤掉所有空行和以
#开头的行 在正则表达式中,
^表示行的开始,$表示行的结尾,那么空行则可以用^$来表示Terminal window $ grep -v '^#' /etc/vsftpd/vsftpd.conf | grep -v '^$'anonymous_enable=YESlocal_enable=YESwrite_enable=YESlocal_umask=022dirmessage_enable=YESxferlog_enable=YESconnect_from_port_20=YESxferlog_std_format=YESlisten=NOlisten_ipv6=YESpam_service_name=vsftpduserlist_enable=YEStcp_wrappers=YES那么,如何打印出不以英文字母开头的行呢? 让我们先来创建一个文件
Terminal window $ vi test.txt123abc456abc2323#laksdjfAlllllllll 然后来查看
Terminal window $ grep '^[^a-zA-Z]' test.txt123456#laksdjf$ grep '[^a-zA-Z]' test.txt123456abc2323#laksdjf 前面也提到过 中括号 [ ] 的应用,如果是数字就用
[0-9]这样的形式(当遇到类似[15]的形式时,表示只含有 1 或者 5) 如果要过滤数字以及大小写字母,则要写成[0-9a-zA-Z]的形式 另外,[^字符]表示除[]内字符之外的字符- 注意:把
^写到方括号的里面和外面是有很大区别的(在外面的是表示首位,在里面的表示”相反”)
- 注意:把
过滤出任意一个字符和重复字符
.表示任意一个字符,r.o表示把r和o之间有一个任意字符的行过滤出来Terminal window $ grep 'r.o' /etc/passwdroot:x:0:0:root:/root:/bin/bashoperator:x:11:0:operator:/root:/sbin/nologin
*表示零个或者多个*前面的字符,ooo*表示匹配 三个o字符,其中前两个o是必须的,最后一个o*表示可以有零个或多个oTerminal window $ grep 'ooo*' /etc/passwdroot:x:0:0:root:/root:/bin/bashlp:x:4:7:lp:/var/spool/lpd:/sbin/nologinmail:x:8:12:mail:/var/spool/mail:/sbin/nologinoperator:x:11:0:operator:/root:/sbin/nologinpostfix:x:89:89::/var/spool/postfix:/sbin/nologin
.*表示零个或者多个任意字符,空行也包含在内,它会把文件里面的所有行都匹配到Terminal window $ grep '.*' /etc/passwd | wc -l21$ wc -l /etc//passwd21 /etc//passwd指定要过滤出字符出现次数
这里用到了符号
{},其内部为数字,表示前面的字符要重复的次数 需要强调的是,{}左右都需要加上转义字符\ 另外,使用
{ }还可以表示一个范围,具体格式为{n1,n2},其中n1<n2,表示重复n1到n2次前面的字符,n2还可以为空,这时表示 ≥n1次Terminal window $ grep 'o\{2\}' /etc/passwdroot:x:0:0:root:/root:/bin/bashlp:x:4:7:lp:/var/spool/lpd:/sbin/nologinmail:x:8:12:mail:/var/spool/mail:/sbin/nologinoperator:x:11:0:operator:/root:/sbin/nologinpostfix:x:89:89::/var/spool/postfix:/sbin/nologin
除了 grep 工具外,我们也会常常用到 egrep 这个工具,后者是前者的扩展版本,可以完成 grep 不能完成的部分工作
假设我们有一个写着以下内容的
test.txtTerminal window
过滤出一个或者多个指定的字符
Terminal window $ egrep 'o+' test.txtrot:x:0:0:rot:/rot:/bin/bashoperator:x:11:0:operator:/root:/sbin/nologinoperator:x:11:0:operator:/root:/sbin/nologinrooooooooooot:x:0:0:rooooooooooooot:/root:/bin/bash$ egrep 'oo+' test.txtrot:x:0:0:rot:/rot:/bin/bashoperator:x:11:0:operator:/root:/sbin/nologinoperator:x:11:0:operator:/root:/sbin/nologinrooooooooooot:x:0:0:rooooooooooooot:/root:/bin/bash$ egrep 'ooo+' test.txtrooooooooooot:x:0:0:rooooooooooooot:/root:/bin/bash 和
grep不同,这里egrep使用的是符号+,他表示匹配 1 个 或 多个+前面的字符,这个+是不支持被grep使用的 包括上面的
{},也是可以直接被egrep使用,而不用加\转义Terminal window $ egrep 'o{2}' /etc/passwdroot:x:0:0:root:/root:/bin/bashlp:x:4:7:lp:/var/spool/lpd:/sbin/nologinmail:x:8:12:mail:/var/spool/mail:/sbin/nologinoperator:x:11:0:operator:/root:/sbin/nologinpostfix:x:89:89::/var/spool/postfix:/sbin/nologin过滤出零个或者一个指定的字符
$ egrep 'o?' test.txtrot:x:0:0:rot:/rot:/bin/bashoperator:x:11:0:operator:/root:/sbin/nologinoperator:x:11:0:operator:/root:/sbin/nologinrooooooooooot:x:0:0:rooooooooooooot:/root:/bin/bash11111111111111111111111111111111111111111111111111111aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
$ egrep 'ooo?' test.txtoperator:x:11:0:operator:/root:/sbin/nologinoperator:x:11:0:operator:/root:/sbin/nologinrooooooooooot:x:0:0:rooooooooooooot:/root:/bin/bash
$ egrep 'oooo?' test.txtrooooooooooot:x:0:0:rooooooooooooot:/root:/bin/bash过滤出字符串 1 或者字符串 2
Terminal window $ egrep 'aaa|111|ooo' test.txtrooooooooooot:x:0:0:rooooooooooooot:/root:/bin/bash11111111111111111111111111111111111111111111111111111aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaegrep中()的应用 这里用
()表示一个整体,下面会把包含rooo或者rato的行过滤出来Terminal window $ egrep 'r(oo|at)o' test.txtoperator:x:11:0:operator:/root:/sbin/nologinoperator:x:11:0:operator:/root:/sbin/nologinrooooooooooot:x:0:0:rooooooooooooot:/root:/bin/bash 也可以把
()和其他符号组合在一起,比如(oo)+就表示 1 个 或者 多个ooTerminal window $ egrep '(oo)+' test.txtoperator:x:11:0:operator:/root:/sbin/nologinoperator:x:11:0:operator:/root:/sbin/nologinrooooooooooot:x:0:0:rooooooooooooot:/root:/bin/bash
2. sed 工具的使用
其实 grep 的功能还不够强大,它实现的只是查找功能,不能把查找出来的内容进行替换,而 sed 是流式编辑器,是针对文档的行来操作的,也能进行内容的替换
2.1 打印某行
格式为 sed -n 'n'p filename 'n' 里面的 n 是一个数字,表示第几行,-n 表示只显示我们要打印的行
$ sed -n '2'p /etc/passwdbin:x:1:1:bin:/bin:/sbin/nologin 要是想把所有行都导引出来,可以使用命令 sed -n '1,$'p filename
$ sed -n '1,$'p /etc/passwdroot:x:0:0:root:/root:/bin/bashbin:x:1:1:bin:/bin:/sbin/nologindaemon:x:2:2:daemon:/sbin:/sbin/nologinadm:x:3:4:adm:/var/adm:/sbin/nologinlp:x:4:7:lp:/var/spool/lpd:/sbin/nologinsync:x:5:0:sync:/sbin:/bin/syncshutdown:x:6:0:shutdown:/sbin:/sbin/shutdownhalt:x:7:0:halt:/sbin:/sbin/haltmail:x:8:12:mail:/var/spool/mail:/sbin/nologinoperator:x:11:0:operator:/root:/sbin/nologingames:x:12:100:games:/usr/games:/sbin/nologinftp:x:14:50:FTP User:/var/ftp:/sbin/nologinnobody:x:99:99:Nobody:/:/sbin/nologinsystemd-network:x:192:192:systemd Network Management:/:/sbin/nologindbus:x:81:81:System message bus:/:/sbin/nologinpolkitd:x:999:998:User for polkitd:/:/sbin/nologinsshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologinpostfix:x:89:89::/var/spool/postfix:/sbin/nologinchrony:x:998:996::/var/lib/chrony:/sbin/nologinmysql:x:27:27:MariaDB Server:/var/lib/mysql:/sbin/nologinnginx:x:997:995:Nginx web server:/var/lib/nginx:/sbin/nologin 当然,我们也可以指定一个区间打印
$ sed -n '1,3'p /etc/passwdroot:x:0:0:root:/root:/bin/bashbin:x:1:1:bin:/bin:/sbin/nologindaemon:x:2:2:daemon:/sbin:/sbin/nologin2.2 打印包含某个字符串的行
$ sed -n '/root/'p test.txtoperator:x:11:0:operator:/root:/sbin/nologinoperator:x:11:0:operator:/root:/sbin/nologinrooooooooooot:x:0:0:rooooooooooooot:/root:/bin/bash 这种用法就类似于 grep 了,在 grep 中使用的特殊字符(如 ^ $ . * 等)
$ sed -n '/^1/'p test.txt11111111111111111111111111111111111111111111111111111
$ sed -n '/in$/'p test.txtoperator:x:11:0:operator:/root:/sbin/nologinoperator:x:11:0:operator:/root:/sbin/nologin
$ sed -n '/r..o/'p test.txtoperator:x:11:0:operator:/root:/sbin/nologinoperator:x:11:0:operator:/root:/sbin/nologinrooooooooooot:x:0:0:rooooooooooooot:/root:/bin/bash
$ sed -n '/ooo*/'p test.txtrot:x:0:0:rot:/root:/bin/bashoperator:x:11:0:operator:/root:/sbin/nologinoperator:x:11:0:operator:/root:/sbin/nologinrooooooooooot:x:0:0:rooooooooooooot:/root:/bin/bash