※この文書は ChatGPT によって翻訳されました
はじめに
今日、人工知能技術の急速な発展に伴い、ローカル環境で大規模言語モデル(LLM)を展開することは、開発者がAIの潜在能力を探求する重要な手段となっています。DeepSeek R1は国産のオープンソースモデルの代表として、その優れた意味理解と生成能力により、ローカルアプリケーションに新たな可能性を提供します。本チュートリアルでは、Ollamaフレームワークを利用して、一般的なパソコン上でDeepSeekモデルをローカルにデプロイする手順を、クラウドの計算資源や複雑なハードウェア構成に頼ることなく、パーソナライズされたAIアプリケーションの開発とテストを実現する方法を、ステップバイステップで解説します。
システム要件
デプロイを開始する前に、以下の条件を満たしていることを確認してください:
- オペレーティングシステム:Windows 10/11 (64ビット) または macOS Monterey (12.0) 以上
- メモリ:最低8GB(推奨は16GB以上で応答速度向上)
- ストレージ:少なくとも20GBの空き容量(モデルファイルは通常10~15GBを占めます)
- ネットワーク:安定したインターネット接続(モデルのダウンロードには帯域幅に応じて5~30分かかります)
- GPU:必須ではありません(推論の高速化が必要な場合は、NVIDIA GPUとCUDA 11+の組み合わせを推奨します)
展開手順の詳細
一、基本環境のセットアップ
1. Ollamaフレームワークのインストール
Windowsユーザー Ollama公式サイト↗ にアクセスして、インストーラをダウンロードし、ダブルクリックで実行してください。 注意:インストール中はウイルス対策ソフトを一時的に停止し、重要なコンポーネントのブロックを避けてください。
macOSユーザー Homebrewを使用して迅速にインストールする:
Terminal window brew install ollama# サービスを起動brew services start ollama
2. モデル保存パスの変更(推奨)
デフォルトでは、Ollamaはモデルをシステムディスク(例:C:\Users\ユーザー名\.ollama)に保存しますが、長期間の使用で空き容量不足になる可能性があります。大容量のパーティションに移動することをお勧めします:
新しいディレクトリの作成(例):
- Windows:
E:\AI_Models\Ollama - macOS:
/Users/ユーザー名/Documents/Ollama
- Windows:
環境変数の設定:
変数名 変数値 OLLAMA_MODELS 新しいディレクトリのフルパス 操作手順:
- Windows:対象の「パソコン」を右クリック → プロパティ → システムの詳細設定 → 環境変数 → ユーザー変数の新規作成
- macOS:
~/.zshrcまたは~/.bash_profileを編集し、export OLLAMA_MODELS="新しいディレクトリパス"を追加
Ollamaサービスの再起動:
Terminal window # Windowstaskkill /im ollama-app.exe /f# macOSkillall ollama
3. インストールの検証
ターミナルまたはコマンドプロンプトを開き、以下のコマンドを入力:
ollama --version# 期待される出力例:ollama version 0.1.18もし「コマンドが見つかりません」と表示された場合は、環境変数の設定を確認してください。 システム環境変数の Path に C:\Users\<ユーザー名>\AppData\Local\Programs\Ollama\(Ollamaのデフォルトインストールパス)を追加することもご確認ください。
二、モデルデプロイ実践
1. 適切なモデルの選択
DeepSeek R1は複数のバージョンのモデルを提供しており、デバイスの性能に応じて適切なものを選択してください:
| モデルバージョン | メモリ要件 | 適用シーン |
|---|---|---|
deepseek-r1:8b | ≥8GB | テキスト生成、基本的な質問応答 |
deepseek-r1:32b | ≥32GB | 複雑な推論、コード生成 |
性能テストツール: DeepSeek互換性検査プラットフォーム(簡体中国語/英語)↗ にアクセスし、デバイスの構成をアップロードして推奨モデルを取得してください。
2. モデルのダウンロード
以下のコマンドを実行して、自動的にモデルをダウンロードおよびロードします(例:8Bバージョン):
ollama run deepseek-r1:8bダウンロードの手順説明:
- 進捗バーによりリアルタイムでダウンロード状況が表示されます(速度はネットワーク帯域幅に依存します)
- 初回ダウンロード時は、約4.9GBのモデルファイル全体を取得する必要があります
- 中断した場合は、
ollama pull deepseek-r1:8b --insecureを実行して再開できます
3. 動作確認
テスト用のコマンドを入力して、モデルが正常に動作しているか確認します:
>>> 日本語で桜の季節についての俳句を書いてください- ここの「日本語で」は大事!じゃないっと、中国語はばっかり出てくる
期待される出力例:
花盛りは春の香りを桜が夜空に落とす光微風に宿らされた春の意地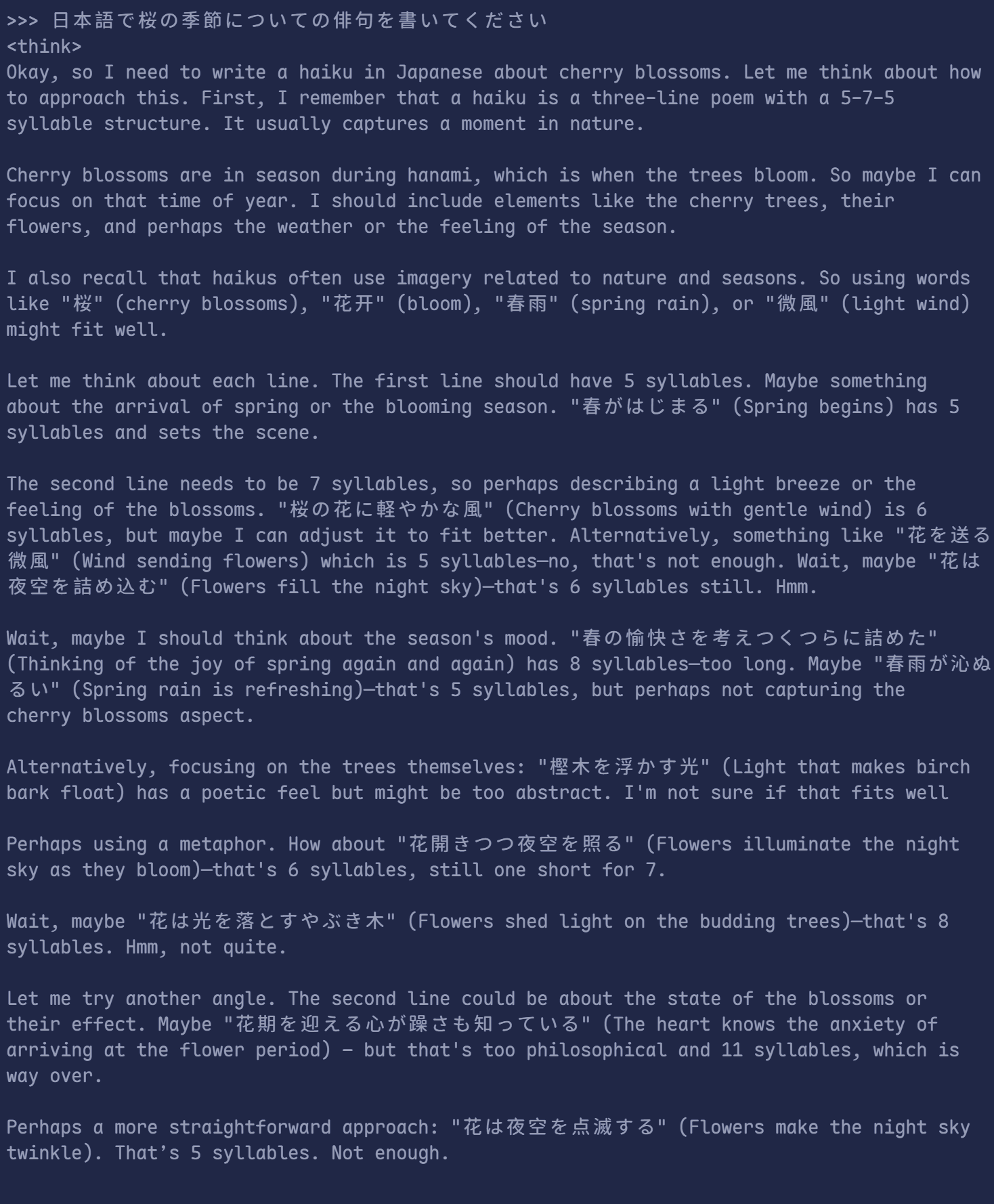


三、インタラクション方式の全解析
1. コマンドラインでのリアルタイム対話
モデルを起動した後、ターミナル上で直接対話できます:
ollama run deepseek-r1:8b> 日本語で日本の伝統文化について説明してください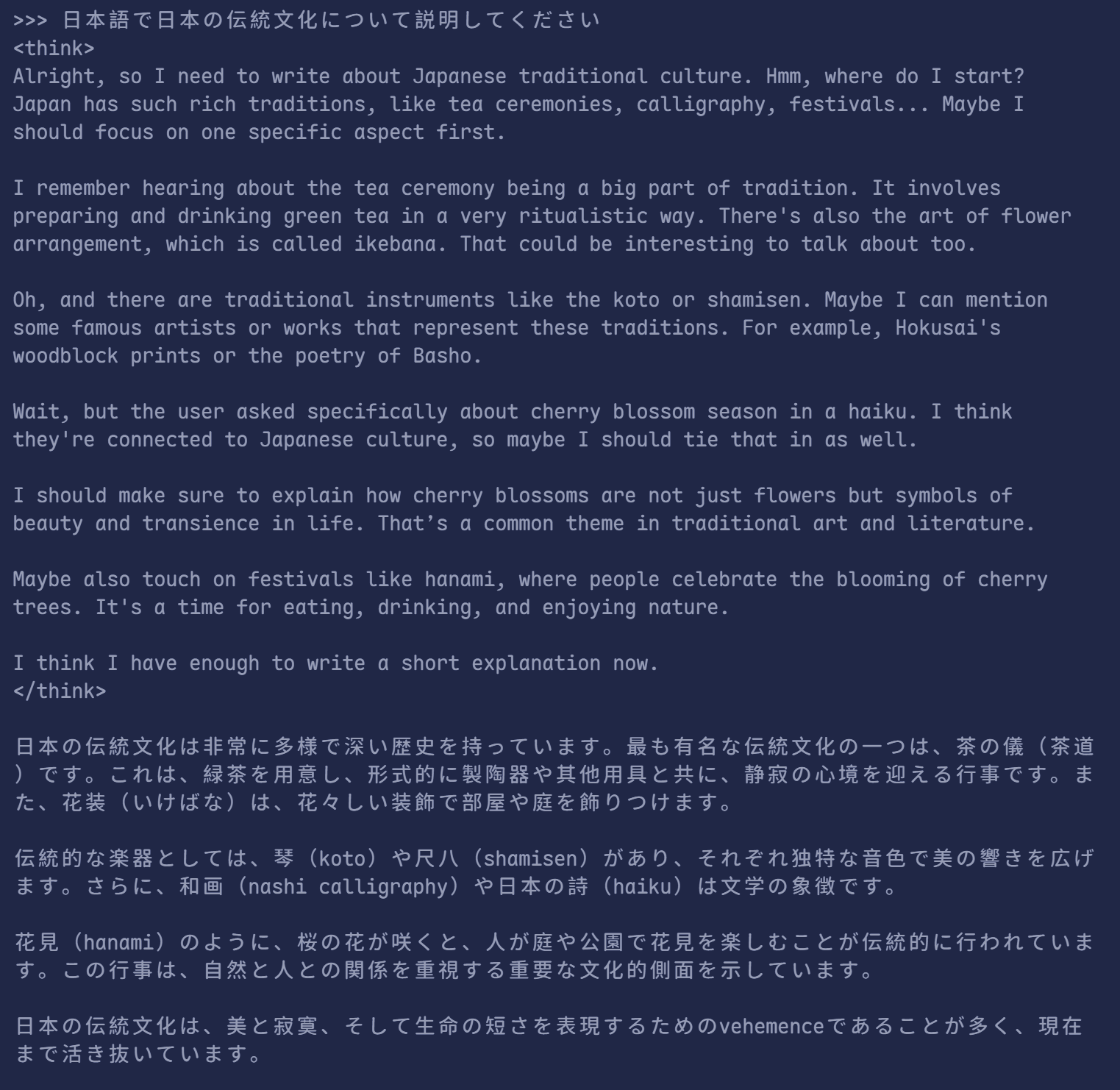
モデルは一文ずつ回答を生成します。/bye または Ctrl+C で終了してください。
2. APIコール(開発統合)
REST APIを通じてプログラムから呼び出すことも可能です:
import requests
response = requests.post( "http://localhost:11434/api/generate", json={ "model": "deepseek-r1:8b", "prompt": "Pythonを用いてフィボナッチ数列を実装してください", "stream": False })print(response.json()["response"])出力例:
def fibonacci(n): a, b = 0, 1 for _ in range(n): print(a) a, b = b, a + bfibonacci(10)3. グラフィカルユーザーインターフェース(オプション)
Ollama WebUI↗ などのオープンソースツールを使用して、視覚的に操作できるインターフェースを作成できます:
docker run -d -p 3000:3000 ghcr.io/ollama-webui/ollama-webui:mainブラウザで http://localhost:3000 にアクセスして、インタラクティブに操作してください。
よくある質問と解決策
Q1:モデルのロード時に「CUDA out of memory」と表示される場合
原因:GPUメモリ不足
解決策:
Terminal window OLLAMA_NUM_GPU=0 ollama run deepseek-r1:8b # CPUモードを強制使用
Q2:応答速度が遅い場合
- 最適化案:
- バックグラウンドでメモリを消費しているプログラムを終了する
- メモリを増設する(例:16GB → 32GB)
- 量子化モデルを使用する(例:
deepseek-r1:8b-q4)
Q3:モデルのダウンロード時に「SSL証明書エラー」と表示される場合
一時的な解決策:
Terminal window ollama pull deepseek-r1:8b --insecure恒久的な解決策:システムのルート証明書を更新するか、ファイアウォールの設定を確認してください。
上級テクニック
1. 複数モデルの管理
インストール済みモデルの一覧表示:
Terminal window ollama list古いバージョンの削除:
Terminal window ollama rm deepseek-r1:8b
2. カスタムファインチューニング
Modelfile を用いてモデルパラメータを調整する:
FROM deepseek-r1:8bPARAMETER temperature 0.7 # 生成のランダム性を制御(0-1)PARAMETER num_ctx 4096 # コンテキストウィンドウの拡大新しいモデルの構築:
ollama create my-deepseek -f Modelfile3. ログ解析と監視
リアルタイムログの確認:
Terminal window tail -f ~/.ollama/logs/server.log # macOS/LinuxGet-Content ~\.ollama\logs\server.log -Wait # Windows PowerShellリソース使用状況の監視:
Terminal window ollama serve --verbose # 詳細な稼働状態を表示
付録
- 公式リソース:
- セキュリティ推奨:
- 定期的にモデルファイルをバックアップする(
OLLAMA_MODELSディレクトリをコピー) - 公共ネットワーク上で
localhost:11434ポートを公開しないように注意する
- 定期的にモデルファイルをバックアップする(
ヒント:デプロイが完了したら、毎週
ollama updateを実行して、パフォーマンスの最適化とセキュリティパッチを適用することをお勧めします。