
ZooKeeper 集群 + Kafka 集群 配置文档
1. ZooKeeper 集群
一、什么是 ZooKeeper 集群
Zookeeper 是一个开源的分布式协调服务框架,主要用于管理分布式系统中的数据一致性和状态同步。Zookeeper 集群由一个领导者(Leader)和多个跟随者(Follower)组成。Leader 负责发起和决议投票,更新系统状态,而 Follower 负责接收客户端请求并返回结果。只要集群中有半数以上的节点存活,Zookeeper 集群就能正常服务。
ZooKeeper 使用类似文件系统的树形结构来储存数据,每个节点称为 ZNode。ZNode 中维护了数据的版本号和访问的控制列表(ACL),确保数据的一致性和安全性。每次数据更新都会生成一个全局唯一的递增事物 ID,保证操作的顺序性
二、ZooKeeper 集群的作用
- 统一配置管理:将配置文件存储在 Zookeeper 中,系统可以监听配置的变化并及时响应。
- 统一命名服务:为资源提供统一的命名服务,类似于域名解析。
- 分布式锁:通过创建临时节点实现分布式锁,确保同一时间只有一个客户端可以获得锁。
- 集群管理:监控集群中节点的状态变化,感知节点的上下线,并进行主从切换。
- 负载均衡:通过监控节点的状态和负载情况,实现负载均衡。
- 主控服务器选举:在集群中选举出一个主控服务器,负责处理写请求和协调其他节点。
三、部署 ZooKeeper 集群
| IP 1(内网网卡) | IP 2(外网网卡) | 主机名 |
|---|---|---|
| 192.168.92.133 | 192.168.75.11 | zookeeper1 |
| 192.168.92.134 | 192.168.75.21 | zookeeper2 |
| 192.168.92.135 | 192.168.75.31 | zookeeper3 |
1. 基础环境配置
1.1 修改主机名
$ hostnamectl set-hostnanme zookeeper1
$ hostnamectl
Static hostname: zookeeper1
Icon name: computer-vm
Chassis: vm
Machine ID: e72e04755f264b69a75c218f22b44031
Boot ID: e4bce8630ce94ddaaa4cc650f83016c1
Virtualization: vmware
Operating System: CentOS Linux 7 (Core)
CPE OS Name: cpe:/o:centos:centos:7
Kernel: Linux 3.10.0-1160.119.1.el7.x86_64
Architecture: x86-64$ hostnamectl set-hostnanme zookeeper2
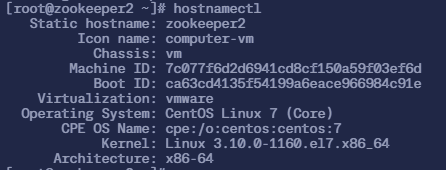
$ hostnamectl
Static hostname: zookeeper2
Icon name: computer-vm
Chassis: vm
Machine ID: 7c077f6d2d6941cd8cf150a59f03ef6d
Boot ID: ca63cd4135f54199a6eace966984c91e
Virtualization: vmware
Operating System: CentOS Linux 7 (Core)
CPE OS Name: cpe:/o:centos:centos:7
Kernel: Linux 3.10.0-1160.el7.x86_64
Architecture: x86-64$ hostnamectl set-hostnanme zookeeper3
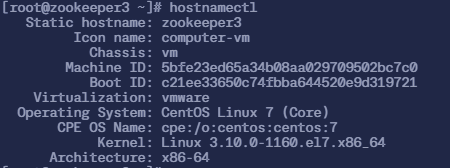
$ hostnamectl
Static hostname: zookeeper3
Icon name: computer-vm
Chassis: vm
Machine ID: 5bfe23ed65a34b08aa029709502bc7c0
Boot ID: c21ee33650c74fbba644520e9d319721
Virtualization: vmware
Operating System: CentOS Linux 7 (Core)
CPE OS Name: cpe:/o:centos:centos:7
Kernel: Linux 3.10.0-1160.el7.x86_64
Architecture: x86-64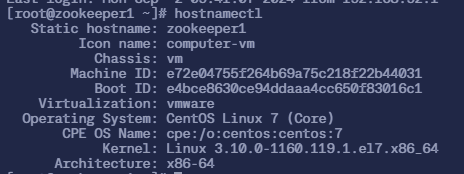
1.2 配置 hosts 文件
修改 /etc/hosts 文件
$ sudo vi /etc/hosts
# 三个机器都增加下面的内容
192.168.92.130 zookeeper1
192.168.92.131 zookeeper2
192.168.92.132 zookeeper3
1.3 配置 YUM 源
# 首先将 3 个节点 /etc/yum.repos.d/ 目录下的所有文件都移动到 /media 目录下
$ sudo mv /etc/yum.repos.d/* /media/
# 然后使用 wget 命令下载 gpmall-repo,然后解压
$ sudo wget https://moka.anitsuri.top/images/gpmall/gpmall-repo.zip
$ sudo unzip gpmall-repo.zip
$ sudo vi /etc/yum.repos.d/local.repo
# 填入以下内容
[gpmall]
name=gpmall
baseurl=file:///opt/gpmall-repo
gpgcheck=0
enabled=1
# 然后刷新 yum 源(清除 yum 缓存 + 展示现在的 repo 列表)
$ sudo yum clean all && yum repolist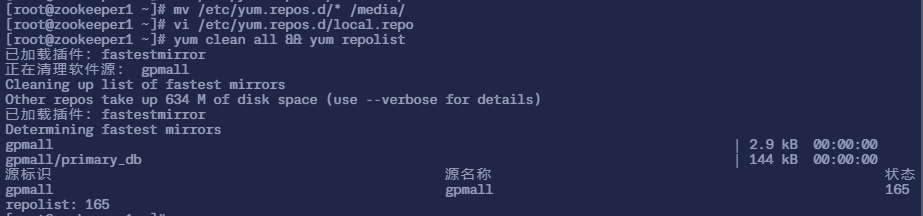
2. 搭建 ZooKeeper 集群
2.1 安装 JDK 环境
3 个节点均安装 Java JDK 环境
$ sudo yum install -y java-1.8.0-openjdk java-1.8.0-openjdk-devel
$ java -version
openjdk version "1.8.0_412"
OpenJDK Runtime Environment (build 1.8.0_412-b08)
OpenJDK 64-Bit Server VM (build 25.412-b08, mixed mode)
2.2 部署 ZooKeeper
2.2.1 下载并解压 ZooKeeper 软件包
# 安装 wget
$ sudo yum install -y wget
# 下载 ZooKeeper 软件包
$ sudo wget https://moka.anitsuri.top/images/gpmall/zookeeper-3.4.14.tar.gz
# 解压 ZooKeeper
$ tar -zxf zookeeper-3.4.14.tar.gz2.2.2 修改配置文件(三个都修改)
$ cd zookeeper-3.4.14/conf/
$ sudo mv zoo_sample.cfg zoo.cfg
$ sudo vi zoo.cfg
# 在下面加入
server.1=192.168.92.133:2888:3888
server.2=192.168.92.134:2888:3888
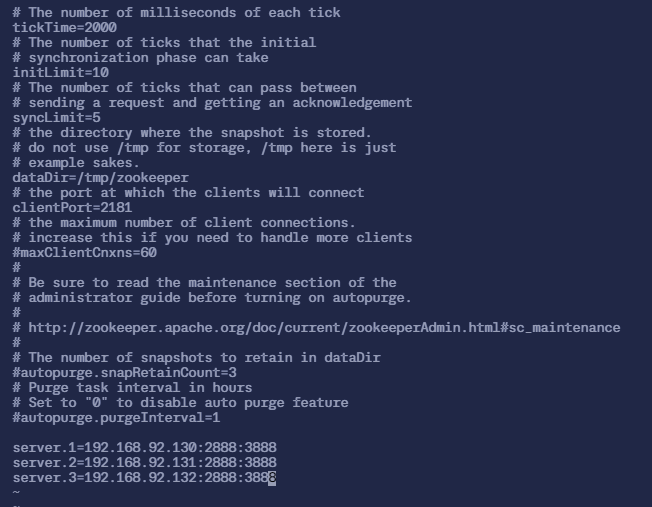
server.3=192.168.92.135:2888:3888# zoo.cfg 的全部内容如下
$ cat zoo.cfg
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/tmp/zookeeper
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
server.1=192.168.92.133:2888:3888
server.2=192.168.92.134:2888:3888
server.3=192.168.92.135:2888:3888- 内容解析
tickTime:tickTime是initLimit和syncLimit两个超时配置的基本单位,例如对于initLimit,其配置值为5,且tickTime为2000时,则说明其超时时间为 2000ms × 5 =10sinitLimit:ZooKeeper 集群模式下包含多个 zk 进程(zk 进程: ZooKeeper 集群中的各个服务器进程),其中一个进程为 leader,余下的进程为 follower- 当 follower 最初与 leader 建立连接时,他们之间会传输相当多的数据,尤其是 follower 的数据落后 leader 很多
initLimit配置 follower 与 leader 之间建立连接后进行同步的最长时间syncLimit:配置 follower 与 leader 之间发送消息,请求与应答的最大时间长度dataDir:用于指定 ZooKeeper 存储数据的目录,包括事务日志和快照(snapshot)
在集群模式下,这个目录还包含一个myid文件,用于标识每个节点的唯一身份(ID),myid文件的内容只有一行,且内容只能为 1~255 之间的数字,这个数字即为<server.id>中的 ID,表示 zk 进程的 ID<server.id>=<host>:<port1>:<port2>:<server.id>:这是一个数字,表示 ZooKeeper 集群中每个节点的唯一标识(ID)。这个 ID 需要与对应节点的myid文件中的内容一致。<host>:这个字段指定了节点的IP地址。在集群内部通信时,通常使用内网IP。<port1>:这是集群中 follower 和 leader 之间进行消息交换的端口。ZooKeeper 集群中,follower 节点通过这个端口与 leader 节点进行数据同步和其他通信。<port2>:这是用于 leader 选举的端口。当集群中的节点需要选举新的 leader 时,它们通过这个端口进行通信。
2.2.3 创建 myid 文件
在 3 台机器的 dataDir 目录(此处应为 /tmp/zookeeper)下,分别创建一个 myid 文件,文件内容分别只有一行,其内容为 1, 2, 3
即文件中只有一个数字,这个数字即为上面 zoo.cfg 配置文件中指定的值
ZooKeeper 时根据该文件来决定 ZooKeeper 集群各个机器的身份分配
$ sudo mkdir /tmp/zookeeper
$ sudo vi /tmp/zookeeper/myid
# 在 zookeeper1 里填入
1
# 在 zookeeper2 里填入
2
# 在 zookeeper3 里填入
33. 启动 ZooKeeper 服务
$ cd /root/zookeeper-3.4.14/bin
# 启动服务
$ sudo ./zkServer.sh start
# 查看状态
# 三台机器都启动了之后再执行这个
$ sudo ./zkServer.sh status zookeeper1 节点
$ sudo ./zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /root/zookeeper-3.4.14/bin/../conf/zoo.cfg
Mode: leader zookeeper2 节点
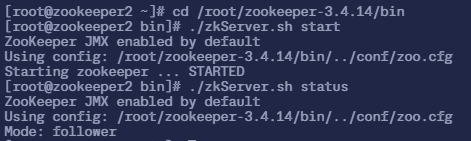
$ sudo ./zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /root/zookeeper-3.4.14/bin/../conf/zoo.cfg
Mode: follower zookeeper3 节点
$ sudo ./zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /root/zookeeper-3.4.14/bin/../conf/zoo.cfg
Mode: follower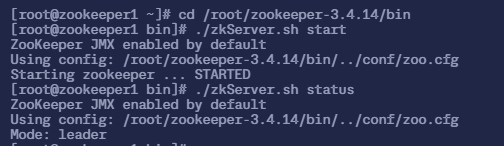
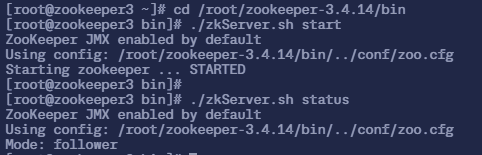
可以看到,3 个节点, zookeeper1 是 leader,其他的都是 follower
至此,ZooKeeper 集群配置完毕
2. Kafka 集群
一、什么是 Kafka 集群
Kafka 集群是由多个 Kafka 服务器(称为 Broker)组成的分布式系统。Kafka 是一种高吞吐量、低延迟的分布式发布订阅消息系统,广泛应用于日志收集、消息系统、实时数据处理等场景。
二、Kafka 集群的作用
Kafka 集群的主要作用包括:
- 高吞吐量和低延迟:Kafka 每秒可以处理数十万条消息,延迟最低只有几毫秒。
- 高可扩展性:Kafka 集群支持热扩展,可以根据需求增加或减少节点。
- 持久性和可靠性:消息被持久化到本地磁盘,并支持数据备份,防止数据丢失。
- 容错性:Kafka 集群允许节点故障,只要有足够的副本,系统仍能正常运行。
- 解耦和消峰限流:Kafka 可以解耦生产者和消费者,缓解系统压力,平滑流量峰值。
通过这些特性,Kafka 集群能够在分布式环境中提供高效、可靠的消息传递和数据处理服务。
三、部署 Kafka 集群
使用 ZooKeeper 集群搭建的 3 个节点来构建 Kafka 集群,因为 Kafka 服务依赖于 ZooKeeper 服务,所以不再多创建机器来进行试验
| IP 1(内网网卡) | IP 2(外网网卡) | 主机名 |
|---|---|---|
| 192.168.92.133 | 192.168.75.11 | zookeeper1 |
| 192.168.92.134 | 192.168.75.21 | zookeeper2 |
| 192.168.92.135 | 192.168.75.31 | zookeeper3 |
1. 配置 Kafka 集群
1.1 下载并解压 Kafka 软件包
在 3 台节点上
# 下载 Kafka 软件包
$ sudo wget https://moka.anitsuri.top/images/gpmall/kafka_2.11-1.1.1.tgz
# 解压 Kafka 软件包
$ sudo tar -zxf kafka_2.11-1.1.1.tgz1.2 修改配置文件
1.2.1 zookeeper1 节点上
$ cd kafka_2.11-1.1.1/config/
$ sudo vi server.properties
# 找到以下内容并在前面添加上井号
broker.id=0 #第21行
zookeeper.connect=localhost:2181 #第123行
# 然后再在下面填上以下三个配置
broker.id=1
zookeeper.connect=192.168.92.133:2181,192.168.92.134:2181,192.168.92.135:2181
listeners=PLAINTEXT://192.168.92.131:9092- 内容解析:
broker.id:每台机器都不一样,相当于在 ZooKeeper 中的<server.id>zookeeper.connect:因为有 3 台 ZooKeeper 服务器,所以这里都得配置上listeners:listeners配置项用于指定 Kafka broker 的监听地址和端口。通常设置为当前节点的内网IP和默认的 Kafka 端口9092

1.2.2 在 zookeeper2 节点上
$ cd kafka_2.11-1.1.1/config/
$ sudo vi server.properties
# 找到以下内容并在前面添加上井号
broker.id=0 #第21行
zookeeper.connect=localhost:2181 #第123行
# 然后再在下面填上以下三个配置
broker.id=2
zookeeper.connect=192.168.92.133:2181,192.168.92.134:2181,192.168.92.135:2181
listeners=PLAINTEXT://192.168.92.134:9092
1.2.3 在 zookeeper3 节点上
$ cd kafka_2.11-1.1.1/config/
$ sudo vi server.properties
# 找到以下内容并在前面添加上井号
broker.id=0 #第21行
zookeeper.connect=localhost:2181 #第123行
# 然后再在下面填上以下三个配置
broker.id=3
zookeeper.connect=192.168.92.133:2181,192.168.92.134:2181,192.168.92.135:2181
listeners=PLAINTEXT://192.168.92.135:9092
2. 启动 Kafka 集群服务
2.1 zookeeper1 节点上
# 安装 screen 服务,以便更好运行 Kafka
$ sudo yum install -y screen
# 使用 screen 服务并创建一个名为 Kafka 的窗口
$ sudo screen -S Kafka
# 进入 Kafka 并启动它
$ cd /root/kafka_2.11-1.1.1/bin/
$ sudo ./kafka-server-start.sh ../config/server.properties
# 然后按 Ctrl+d 键最小化窗口
# 最小化窗口后查看 Java 进程
$ jps
1637 QuorumPeerMain
2139 Kafka
2463 Jps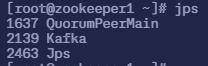
2.2 zookeeper2 节点上
# 安装 screen 服务,以便更好运行 Kafka
$ sudo yum install -y screen
# 使用 screen 服务并创建一个名为 Kafka 的窗口
$ sudo screen -S Kafka
# 进入 Kafka 并启动它
$ cd /root/kafka_2.11-1.1.1/bin/
$ sudo ./kafka-server-start.sh ../config/server.properties
# 然后按 Ctrl+d 键最小化窗口
# 最小化窗口后查看 Java 进程
$ jps
1618 QuorumPeerMain
2102 Jps
1771 Kafka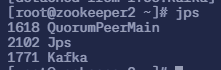
2.3 zookeeper3 节点上
# 安装 screen 服务,以便更好运行 Kafka
$ sudo yum install -y screen
# 使用 screen 服务并创建一个名为 Kafka 的窗口
$ sudo screen -S Kafka
# 进入 Kafka 并启动它
$ cd /root/kafka_2.11-1.1.1/bin/
$ sudo ./kafka-server-start.sh ../config/server.properties
# 然后按 Ctrl+d 键最小化窗口
# 最小化窗口后查看 Java 进程
$ jps
2247 Jps
1692 QuorumPeerMain
1916 Kafka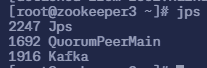
3. 测试 Kafka 服务
在 zookeeper1 节点
$ cd /root/kafka_2.11-1.1.1/bin/
# 创建 topic 命令
$ sudo ./kafka-topics.sh --create --zookeeper 192.168.92.133:2181 --replication-factor 1 --partitions 1 --topic test
Created topic "test"- 如果成功的话,会输出
Created topic "test"

虽然 topic 是在 192.168.92.130 上创建的,但是在其他机器上也能看到,所以可以用其他机器查看到 zookeeper1 机器上查看 topic
在 zookeeper2 节点 和 zookeeper3 节点上
$ cd /root/kafka_2.11-1.1.1/bin/
$ sudo ./kafka-topics.sh --list --zookeeper 192.168.92.133:2181
test- 如果成功的话,则会显示
test


测试成功
如果想要有完整的观看体验,请点击这里
Comments NOTHING